
LES BASES DE DONNEES OBJETS
Introduction
Nous avons vu dans le premier chapitre consacré à la productique que le concept de base de données d'ingénierie peut jouer un rôle fondamental dans l'architecture d'un système de productique. En effet, trois aspects essentiels des problèmes d'ingénierie sont la complexité des données, le grand volume ainsi que le besoin de conservation de ces données, et la nature coopérative du travail en ingénierie. Pour résoudre tous ces problèmes, il faut faire appel à la technologie des bases de données.
Dans ce cadre nous verrons comment peuvent être résolus les quatre problèmes fondamentaux de représentation, de stockage, de partage et d'administration des données d'ingénierie au sein d'une base de données.
Définitions
Après avoir défini le terme "base de données", présenté ses fonctions et introduit les concepts essentiels de cette technologie, nous ferons rapide historique des différents modèles existants (hiérarchique, réseau, relationnel, objet).
Base de données et ingénierie
Le cadre de notre réflexion étant l'utilisation de base de données dans le domaine de la productique et de l'ingénierie, nous verrons quelles sont les spécificités liées à ce domaine, et comment celles-ci se traduisent en terme de nouveaux besoins (de nouvelles fonctionnalités) au niveau des systèmes de gestion de bases de données.
En partant d'un exemple simple mais représentatif de données manipulées en ingénierie, nous montrerons comment l'on peut représenter et stocker ces informations dans les différents types de base de données "traditionnelles". Cela nous amènera à montrer les limitations de ces modèles et, toujours en nous situant dans le cadre de l'approche objet, à présenter une nouvelle approche : les bases de données objet.
Représentation : langage objet et base de données
Dans le cas des bases de données objets, la représentation se fera naturellement à l'aide d'un modèle et d'un langage orienté objet. Cette première caractéristique se traduit par l'existence d'un certain nombre de propriétés classiques issues des langages objets.
- l'existence de classes ou de types
- l'existence d'un mécanisme d'héritage ou de délégation
A ces propriétés, on doit en ajouter de nouvelles, provenant de l'aspect base de données.
- possibilité de faire des requêtes associatives (query capability).
Enfin, les données d'ingénierie necessitent en plus de pouvoir représenter.
Persistence
Une base de donnée se doit d'assurer un stockage persistent et stable des données. Pour cela, il est necessaire de mettre en uvre des mécanismes de stockage et de reprise sur panne (recovery).
Partage des données
Un véritable système de gestion de base de données se doit de posséder un mécanisme de contrôle de concurrence (concurrency control). Ce mécanisme a pour objet d'empêcher que plusieurs utilisateurs accédant simultanément aux mêmes données rendent la base incohérente. Nous verrons que les bases de données d'ingénierie doivent supporter de nouveaux types de transactions : transactions longues, transactions imbriquées, transactions coopératives.
Les bases de données
Définitions
Un Système de gestion de base de données est un outil permettant de gérer une collection de données interdépendantes, partagées entre plusieurs utilisateurs ou applications, stockées de façon persistante et de manière indépendante des programmes qui les utilisent. Un système de gestion de base de données, est un outil qui est le gestionnaire et le dépositaire persistant et partageable d'un ensemble d'objets.
Dépositaire persistant : une base de données doit avant tout être considérée comme un dépositaire, c'est-à-dire quelque chose à qui l'on peut confier des objets, et à qui l'on peut faire confiance pour qu'il conserve ces objets en bon état, d'où la notion de persistance.
Dépositaire partageable : ce dépositaire doit être partageable, car de nombreuses personnes sont à même de lui confier des objets, et de les échanger par son intermédiaire.
Gestionnaire : une base de données est responsable de la gestion de ces données, car c'est elle seule qui connaît où et comment sont rangées les données qui lui ont été confiées.
Objets et relations : enfin, c'est un système qui stocke et gère non seulement des données, mais aussi, et c'est là un point fondamental, les relations ou liens entre ces données. L'existence de relations entre objets est ce qui différencie une véritable base de données d'un simple gestionnaire de fichiers.
D'autre part, une base de données doit répondre à des critères d'intégration, de flexibilité et de disponibilité :
Intégration : toutes les données sont regroupées, et chaque application n'utilise que celles dont elle a besoin. De nouvelles applications peuvent facilement s'ajouter au système. Toutes les données étant regroupées, et n'existant qu'en un seul exemplaire, les risques d'incohérence sont diminués.
Flexibilité : l'utilisation des données ne dépend pas de leur organisation physique ni de leurs chemins d'accès. Les utilisateurs ne voient que la structure logique des données, et n'ont pas à se préoccuper des détails d'implantation.
Disponibilité : chaque utilisateur voit l'ensemble de la base comme s'il en était le seul utilisateur. Le mécanisme de gestion des accès concurrents isole le travail de chacun.
Fonctions d'un SGBD
Un système de gestion de base de données doit assurer trois grandes fonctions:
- une f onction de description qui doit permettre de décrire les données ou entités manipulées.
- une fonction de manipulation qui doit permettre aux utilisateurs (ou aux programmes applicatifs) de créer, de retrouver, de modifier ou de supprimer les données dans la base.
- une fonction de contrôle qui doit garantir l'intégrité, la sécurité et la confidentialité des données dans la base.
Niveaux de représentation
De façon classique, on distingue trois niveaux pour la modélisation de la structure d'une base de données.
Le niveau externe ou logique
C'est le niveau des données directement manipulées par les utilisateurs. Comme tous les utilisateurs n'ont pas les mêmes besoins, on définit à ce niveau ce que l'on nomme des vues, chargées de représenter les données dans un formalisme correspondant aux besoins des utilisateurs.
Le niveau conceptuel
Ce niveau permet de représenter de façon abstraite (sans se soucier des détails d'implantation) l'ensemble des données en intégrant les besoins (et donc les vues) de tous les utilisateurs. Il définit par un schéma conceptuel l'ensemble de toutes les données nécessaires à la modélisation du niveau logique.
Historique des bases de données
Les premiers systèmes de gestion de base de données sont apparus vers la fin des années 60 pour permettre de pallier au manque de souplesse des systèmes d'information qui étaient alors uniquement basés sur l'utilisation de fichiers. Se sont ainsi succédés trois grands modèles : le modèle hiérarchique, le modèle réseau et le modèle relationnel.
Le modèle relationnel, directement issu des travaux de E.F. CODD, est actuellement le plus utilisé. Il commence néanmoins à montrer ses limites. Les bases de données relationnelles ont été tout d'abord conçues pour être utilisées dans des applications de gestion traditionnelles, où la représentation des données sous forme de tables est bien appropriée. L'essor de nouveaux types d'applications telle que la CFAO, le génie logiciel, les systèmes d'informations géographiques, qui manipulent des objets complexes et variés, nécessite l'utilisation d'un nouveau modèle. Certains auteurs ont proposé des extensions permettant d'aller au delà du modèle relationnel : modèle relationnel étendu, bases de données extensibles, base de données sémantiques.
Un autre courant se dégage aujourd'hui nettement, résultat des travaux réalisés en génie logiciel et en intelligence artificielle, et basé sur le concept d'objet. Ce nouveau modèle est celui des bases de données objets.
Base de données et ingénierie
Support de données complexes
De façon générale, les structures de données utilisées sont de type graphe d'objets interconnectés par de nombreux pointeurs en mémoire. Ces pointeurs vers les objets servent de référence, et sont passé comme paramètres dans les procédures. On souhaite pouvoir stocker sur disque les objets tels qu'ils sont en mémoire, en conservant directement la notion de pointeurs entre objets.
Support de travail coopératif
Aspect multi-niveaux
Lorsqu'un groupe de personnes coopère à la réalisation d'un travail commun, leur activité est en général organisée de façon à répartir le travail entre les différentes personnes. Cette organisation vise en général à fractionner ce travail en tâches les plus indépendantes possibles, pour permettre une bonne indépendance entre les différents intervenants. Ce besoin d'organisation doit également se retrouver au niveau de l'architecture des systèmes d'informations.
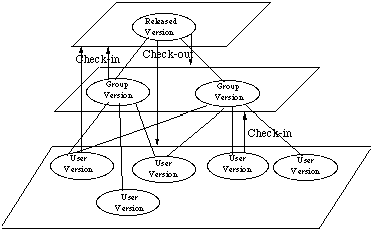
Dans le domaine du génie logiciel et celui des bases de données objets, une architecture couramment proposée comprend trois niveaux différents.
· Un niveau privé (user level) : c'est à ce niveau que la plus grande partie du travail est effectué. Un utilisateur y travaille seul sur les données dont il a la charge.
· Un niveau groupe ou projet (group level) : il correspond à une situation intermédiaire ou le travail d'un individu est considéré comme suffisamment avancé pour être partagé et utilisé par d'autres membres du groupe. C'est à ce niveau que se réalise l'intégration du travail de chacun des participants.
· Un niveau d'exploitation (release level) : à ce niveau le travail est considéré comme suffisamment abouti et stabilisé pour pouvoir être utilisé de façon sure par l'ensemble des utilisateurs.
Ces différents niveaux allant du plus particulier (le niveau privé) au plus général (le niveau d'exploitation) correspondent souvent au différentes étapes de réalisation d'un produit, depuis l'idée originale (le produit virtuel), jusqu'au produit fabriqué et assemblé.
On passe d'un niveau à un autre par deux opérations fondamentales :
- l'opération de check-out permet de faire une copie locale des données dans une base de travail. Il est alors possible de les modifier de façon indépendante sans risque de corrompre les données d'origine et sans empêcher d'autres utilisateurs d'y accéder.
- l'opération inverse de check-in permet, une fois le travail sur les données dans la base locale validées, de basculer ces données dans une base de niveau supérieur ou elle pourront alors être utilisées par d'autres.
Aspect multi-états
Au sein de la fédération de bases de données de l'entreprise, le passage d'une base à une autre (par exemple d'une base personnelle à une base départementale) sera en général soumis à un processus de contrôle et de validation. Elle se traduira par une modification de l'état ou du statut des données. Dans une base de données techniques, les informations auront donc en général plusieurs états, correspondants à différents niveaux de contrôle et de validation. A ces différents états seront attachés des droits d'accès spécifiant la visibilité de cette donnée.
Contrairement à la précédente notion de niveaux (qui était liée au processus de conception) la notion d'état est plus directement liée à la gestion et à l'exploitation de la base de données. Elle permet en effet de faire la différence entre un état stabilisé et validé de la base directement utilisée dans un processus industriel (base de production ou d'exploitation), et un état en cours de définition mais non encore validé (base de travail ou base de test).
Le passage (basculement) de la base de test à la base de production est alors un processus rigoureux qui doit s'accompagner de nombreuses précautions, afin de ne pas perturber le bon fonctionnement du système utilisant la base de production.
Comparaison des différents modèles
Pour mieux illustrer notre discourt, nous allons prendre comme exemple la définition d'une pièce composite (voir figure 18).
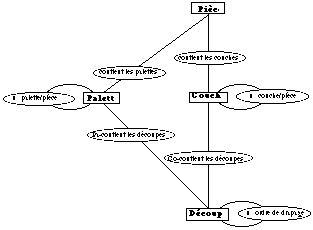
Diagramme Entité-Association de l'exemple.
Une pièce est constituée d'un certain nombre de couches, ces couches pouvant elles-mêmes être constituées de plusieurs découpes.
D'autre part, pour la fabrication, les découpes constituant une pièce sont regroupées en palettes, en respectant l'ordre de drapage des découpes. Il faut en général plusieurs palettes pour draper la totalité des découpes d'une pièce.
Les Fichiers
Un système de gestion de fichiers, n'est pas à proprement parler un système de gestion de base de données. Cela dit, tous les langages de programmation permettent de manipuler des fichiers. On y retrouve en général des fonctions pour ouvrir et fermer un fichier (fonction open et close), et des fonctions pour lire et écrire dans ce fichier (fonctions read et write). Une solution simple peut donc consister à s'appuyer sur le système de gestion de fichiers du système d'exploitation, en y ajoutant une couche applicative.
Stockage
Une première solution simple pour utiliser un système de gestion de fichier comme une base de donnée est d'utiliser un fichier par entité, et de représenter les relations entre entités en utilisant les possibilités de hiérarchisation du système de répertoires. On ne peut alors représenter que des relations de types hiérarchiques.
L'utilisation du système de liens logiques disponible notamment sous UNIX peut éventuellement permettre de représenter des relations plus complexes.
>Palette1 // directory palette1
.palette1 / // fichier palette1
Decoupe1 // lien logique vers le fichier Decoupe1
Des logiciels tels que c-news [Collyer & Spencer 87] ou inn [Salz 92] font une utilisation assez semblable du système de fichier d'UNIX pour assurer la gestion des articles postés sur Usenet.
Toute la gestion des relations est alors déportée dans l'applicatif, et celui-ci est alors à la merci du moindre changement au niveau physique (changement du nom d'un fichier, ou de son répertoire).
Une autre possibilité de stockage consiste à écrire l'ensemble des objets en block dans un seul et même fichier. C'est notamment l'option utilisée dans le Standard d'Échange et de transfert (SET), et dans le standard STEP/PDES. Il est alors nécessaire d'utiliser des indicateurs (tags) à l'intérieur du fichier pour représenter des références multiples sur un même objet.
En Lisp, on pourra par exemple stocker l'ensemble de la structure d'une pièce en l'écrivant tout simplement dans un fichier texte. La fonction d'écriture (print) de Lisp se chargera de générer les références internes nécessaires sous la forme de #Num= pour la définition d'une référence, et de #Num# pour pointer sur un objet précédemment référencé.
(#1=#S(DECOUPE :NOM D1) #2=#S(DECOUPE :NOM D2)
:LISTE-DECOUPE (#4=#S(DECOUPE :NOM D4) #5=#S(DECOUPE :NOM D5)))
(#6=#S(DECOUPE :NOM D6) #7=#S(DECOUPE :NOM D7)
(#S(PALETTE :NOM P1 :LISTE-DECOUPE (#1# #2# #3# #4# #5#))
#S(PALETTE :NOM P2 :LISTE-DECOUPE (#6# #7# #8#))))
Le chargement du fichier par la fonction de lecture (read) permettra de reconstruire en mémoire la totalité du graphe d'objet. Cette technique est bien appropriée à l'archivage ou aux échanges de données.
Partage des données
Sous UNIX, la distribution et la répartition des donnés sur un réseau peuvent se faire en utilisant le système de partages de fichier NFS. Celui-ci étant implanté sous la forme de serveurs sans états, il est néanmoins difficile d'assurer qu'une modification touchant plusieurs fichiers répartis sur le réseau a bien été effectuée.
Toujours sous UNIX, l'aspect multi-utilisateurs peut partiellement être pris en compte en utilisant le système de verrouillage LOCKD. Ce système permet de poser des verrous sur les fichiers, mais ces verrous sont uniquement indicatifs, donc contournables par d'autres applications. De plus LOCKD ne permet pas réellement de faire de la détection de verrous mortels (dead-lock).
Les bases de données hiérarchiques
Un système de gestion de base de données hiérarchiques représente les données sous la forme d'arbres composés d'une hiérarchie d'enregistrements contenant les données. Chaque enregistrement, appelé segment est lui même constitué d'un certain nombre d'attributs ou champs. Les segments sont organisés sous la forme d'arbres de segments, qui à un segment père fait correspondre un nombre quelconque de segments fils. Une base hiérarchique est alors constituée par un ensemble d'arbres, dont les nuds sont des segments [Gardarin 92].
Les bases de données hiérarchiques permettent bien de représenter les arborescences de type ensemble, sous-ensemble que l'on rencontre en C.A.O. Il est donc possible de représenter facilement notre arborescence Pièce / Couche / Découpe, et Pièce / Palette / Découpe ( See Base hiérarchique. ).

Base hiérarchique.
Dans ce type de base de données, il n'est pas possible de représenter des relations horizontales, comme la relation qui ordonne les différentes couches entre elles suivant leur ordre de drapage. Donc, pour représenter entièrement un problème, il est nécessaire de dupliquer certaines données : par exemple ici on est obligé de dupliquer les découpes celles-ci font à la fois partie de l'arborescence Pièce / Couche / Découpe et Pièce / Palette / Découpe.
L'utilisation d'une base hiérarchique se fait en déplaçant un ou plusieurs pointeurs ou curseurs dans un parcourt de la base de la racine vers les fils. Ces curseurs permettent de mémoriser un positionnement sur un segment particulier dans l'arborescence de la base, et d'effectuer des manipulations (lecture, écriture, etc. ) sur ce segment. L'accès aux données (aux segments) est navigationnel et suppose donc la connaissance de la structure physique de la base.
Les bases de données réseau
Un système de gestion de base de données réseau représente les données sous la forme d'enregistrement ou article (Record) contenant un ensemble d'agrégats (vecteur ou groupe répétitif) constitués eux même d'atomes ceux-ci constituant la plus petite unité de données manipulable. Les bases de données réseau sont une extension des bases de données hiérarchiques en ce sens qu'elles permettent de représenter d'autres types de relations que les relations verticales ensemble/sous-ensemble.
Ici, on a représenté les différentes couches constituant une pièce sous la forme d'une liste chaînée de couches, et d'une liste chaînée de palettes ( See Base réseau. ).
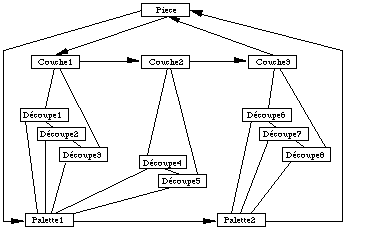
Base réseau.
Les bases de données réseau permettent de modéliser tous les types de relations, c'est en fait le premier modèle de base de données réellement complet. Il présente néanmoins un certain nombre de désavantages dont le principal est que, comme dans le cas des bases de données hiérarchiques, l'accès aux données est navigationnel et est totalement lié à la structure physique de la base.
Les bases de données relationnelles
Les bases de données relationnelles sont basées sur la théorie mathématique de l'algèbre relationnelle. Dans cette théorie relationnelle, une relation est représentée par l'ensemble des lignes d'une table.
On a donc l'équivalence fondamentale RELATION = TABLE
Les relations (donc les tables) étant considérées au sens ensembliste, il n'existe aucune notion d'ordre au sein d'une relation. L'ordre des lignes dans une table est donc quelconque. Les relations sont manipulées en utilisant les différents opérateurs de l'algèbre relationnelle.
La manipulation des données se font à l'aide du langage SQL, qui implante l'ensemble des opérateurs de l'algèbre relationnelle. Le langage SQL (Structured Query Language) est un langage qui a pour origine le système R d'IBM. C'est un langage non procédural qui permet la définition des données, la manipulation des données, et le contrôle des données.
Stockage
Une première solution pour stocker notre graphe d'objet est d'utiliser une table par classe d'objet et d'attribuer à chaque objet une clef permettant de l'identifier ( See Stockage dans une base relationnelle. ).
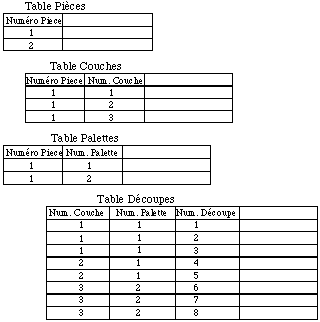
Stockage dans une base relationnelle.
Les relations entre les différents objets seront alors dynamiquement reconstruites par jointure entre les différentes tables. La navigation dans le graphe d'objet demandera de nombreuses jointures, ce qui pose alors de grave problème en terme de performances.
Une seconde possibilité, parfois utilisée, consiste à écrire d'un bloc l'ensemble d'un graphe d'objet sous la forme d'un unique objet binaire stocké directement dans un champ de longueur variable d'une table relationnelle.
Cette solution permet de bénéficier des possibilités d'indexation, de requêtes associatives, ainsi que de contrôle de concurrence des bases de données relationnelles. Elle ne résout néanmoins pas directement le problème du stockage d'objets de type graphes. Il est en effet dans ce cas nécessaire de développer mécanisme de type "flatener" permettant de mettre à plat une structure de type graphe.
Notion de mauvaise adaptation d'impédence (impedance mismatch)
De façon générale, les notions de tables, lignes et colonnes que l'on trouve dans une base relationnelle correspondent bien à la façon de penser des utilisateurs dans des domaines tels que la gestion. Ces bases de données s'avèrent pourtant vite limitées lorsqu'il faut les utiliser pour bâtir des applications complexes. On se heurte alors à trois grands problèmes :
- il n'est pas possible de gérer des groupes et des champs de longueur et d'occurrence variable dans un même enregistrement.
- la gestion des relations entre tables devient vite très difficile lorsque le nombre de tables devient important.
- la décomposition en de nombreuses tables liées au procédé de normalisation fait perdre une très grande partie du contenu sémantique des structures du monde réel que la base est censée représenter.
Il y a donc de plus en plus une inadéquation entre les objets complexes manipulés par les langages de programmation modernes (Lisp, Smalltalk, C++), et les possibilités offertes par les bases de données relationelles. On désigne habituellement ce problème sous le terme "d'impedance mismatch" ( See Notion "d'impedance mismatch". ).

Les bases de données objets
L'apparition de la notion de base de données objets provient du fait qu'un ensemble de fonctionnalités n'était pas simultanément couvert par les langages objets, et les bases de données "classiques".
Au niveau des langages objets
Les langages objets ont largement prouvé leur intérêt dans les domaines de la représentation des connaissances [Greiner & Lenat 80] et en intelligence artificielle, mais ils ont encore des lacunes dans les domaines suivants :
Au niveau des bases de données
Les bases de données "classiques" (hiérarchiques, réseaux, relationnelles) sont aujourd'hui largement utilisées et ont montré leur capacité à manipuler de très importants volumes de données, et à partager ces données entre de nombreux utilisateurs. Mais on peut noter à leur égard quelques points posant encore des problèmes :
- type de données simples (Nombre, Chaîne, date, etc....) et non extensibles
- difficultés pour représenter des données ayant une structure complexe
- difficultés pour représenter des données ayant une taille variable
Par rapport au modèle relationnel, les bases de données objets peuvent sembler d'une certaine façon faire un retour en arrière vers le modèle réseau. Nous verrons qu'une des plus grandes différences réside dans la notion d'identité d'objet. Chaque objet se voit attribué un identifiant unique, indépendant du type de l'objet (de sa classe), et de sa localisation physique (en mémoire ou sur disque). Les relations entre objets ne sont plus sous la forme de pointeur sur des enregistrements (pointeur physique), mais utilisent les identifiants des objets (pointeur logique). Il existe donc un niveau d'indirection, ce qui rend les mises à jours beaucoup plus simples.
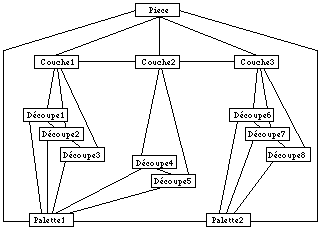
Base objet.
Nous verrons plus loin qu'il existe trois différentes approches pour construire une base de données objets.
(1) Extension d'une base de données "classique" vers le modèle objet
(2) Doter un langage objet "classique" de capacité de stockage
(3) Créer un nouveau langage en privilégiant à la fois la richesse du modèle de représentation et l'efficacité du stockage disque
Comparaison relationnel/objet
Plusieurs auteurs ont effectué une comparaison pratique des bases de données relationnelles et des bases de données objets [Ketabchi et al 90]. Tous ont montré la supériorité de ces dernières, qui se traduit par les remarques suivantes.
· Le schéma d'une base de données objets est plus facile à appréhender que celui d'une base de données relationnelle, car il est mieux structuré, il contient plus de sémantique, et il est plus proche des entités réelles.
· L'utilisation de l'héritage permet de mieux structurer le schéma, et de factoriser certain de ses éléments. La possibilité qu'a le concepteur de définir de nouveaux types et de nouvelles opérations permet de mieux capturer la sémantique du problème traité, et ainsi de représenter quasi directement les entités à modéliser.
· Le fait que les objets possèdent une identité propre, permet de supprimer tout les champs clefs introduits souvent de façon artificielle dans le modèle relationnel lorsque l'on veut que celui-ci soit normalisé en troisième forme normale. Le schéma est donc plus simple.
· Grâce aux capacités d'encapsulation et d'abstraction du modèle objet, il est possible de beaucoup mieux découpler les applications de l'implantation de la base de données, et donc d'avoir une bonne indépendance logique. Les objets ne sont en effet vus qu'au travers leurs interfaces, et seul le changement de ces interfaces ont une répercussion sur le code des applications. Grâce à l'encapsulation, toute modification de l'implantation interne des objets est transparente.
Modèle objet
Une base de données objet suppose tout d'abord l'existence un langage objet permettant de représenter les données stockées dans la base. Nous allons ici étudier les propriétés spécifiques que doit présenter un tel langage.
L'approche consistant à utiliser un langage de manipulation de données de type SQL pour accéder a une base de données objet depuis un langage de programmation semble tout à fait inefficace si ce langage est lui même aussi un langage objet. On désirerait en effet cacher le plus possible les différences de syntaxes entre les objets en mémoire et les objets sur disque.
En général, il n'est par contre pas possible de cacher les différences sémantiques entre ces deux types de représentations, surtout si les objets en base de données doivent être accédés par plusieurs langages orientés objets différents en même temps, ces langages reposant sur des modèles objets n'ayant pas la même sémantique. D'un autre coté, il semble que la majorité des langages orientés objets possèdent un certain nombre de traits sémantiques communs qui sont en fait le cur de l'approche objet [Fishman et al 87].
Il semble donc qu'un modèle objet bien choisi, serait capable de s'adapter facilement à une grande variété de langages objets. Une analyse des caractéristiques d'un certain nombre de langages objets a montré qu'ils ont en commun quatre types d'opérations élémentaires sur les objets :
- Une opération de création d'un nouveau type et son placement dans la hiérarchie des types
- Une opération permettant de définir une nouvelle opération sur un type
- Une opération permettant de créer (ou de détruire) une nouvelle instance d'objet
- Une opération permettant d'exécuter une opération sur un objet
Un modèle objet proposant des interfaces pour chacune de ces opérations pourra donc assez facilement s'adapter à la sémantique propre de langages objets différents.
Identité
Un corollaire du principe de réification est qu'un objet se doit d'avoir un identifiant qui lui soit propre. Cet identifiant restera lié à l'objet durant toute la durée de sa vie (informatique), quel que soit les modifications apportées à cet objet.
Les objets doivent donc théoriquement se voir attribuer un identifiant unique (UID = Unique IDentifier) ne dépendant ni du type (classe) ou du contenu de l'objet, ni de sa localisation physique [Khoshafian & Copeland 86].
Remarque : ce tableau nous montre que ce n'était pas le cas dans les générations précédantes de bases de données. Dans les bases hiérarchiques et réseaux, les identifiants utilisés sont les numéros d'enregistrement, qui dépendent donc de la localisation physique de cet enregistrement dans la base. Dans les bases relationnelles, un objet est identifié par un tuple d'attributs clefs et donc par son contenu. Par exemple on identifie une personne par ses attributs Nom, Prénom. Si la personne change de nom, ce n'est plus la même personne !
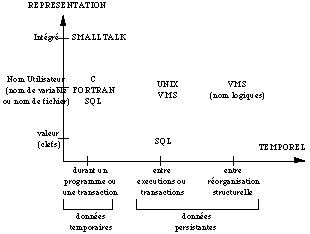
Les différents niveaux d'identité.
L'identifiant d'un objet ne doit pas contenir d'information précisant son emplacement physique ("location independance"). Cette information doit au contraire être obtenue dynamiquement par le client. Cela doit entre autres permettre que des opérations d'administration tel que l'ajout ou le retrait de serveurs, ou la redistribution de fichiers soit transparente pour l'utilisateur. Il est à noter que dans le cas d'une base de données répartie (plusieurs serveurs sur un réseau), il n'est pas trivial de générer des identifiants uniques indépendants de la localisation des objets sur le réseau (notion de "location transparency").
Nous verrons en abordant le problème du stockage des objets que cela oblige en général à utiliser un double ensemble d'identifiants : l'un pour les adresses mémoire, l'autre pour les adresses disque.
Persistance
Un des points fondamentaux concernant la persistance est de savoir comment est rendu persistant un objet. Quel est la différence entre un objet persistant et un objet volatile? Comment et à quel moment passe-t-on de l'un à l'autre? De façon idéale, la persistance d'un objet doit être une caractéristique orthogonale aux autres caractéristiques de l'objet. C'est-à-dire que la persistance ne doit pas dépendre du type de l'objet, et doit pouvoir être réversible.
Il existe plusieurs possibilités pour rendre un objet persistant :
· Par instantiation à partir d'une classe persistante
Une classe souvent située a la racine du graphe d'héritage définie la propriété de persistance. Tout objet qui est une instance de cette classe ou de ces sous-classes hérite alors de cette propriété et est rendu persistant. Cette solution ne respecte bien sur pas le principe d'orthogonalité. Elle conduit le plus souvent à développer deux hiérarchies parallèles d'objets, une pour les objets volatiles, et une pour les objets persistants.
Soit l'on crée l'objet avec un paramètre supplémentaire pour indiquer qu'il doit être rendu persistant. Soit on utilise une commande spéciale qui crée cet objet en base de donnée.
· Par envoi de message rendant l'objet persistant.
C'est en quelque sorte une extension de la méthode précédente, qui permet à tout moment de redéfinir la persistance de l'objet par envoi de messages.
· Par stockage dans une zone définie comme persistante.
On définit certaines variables comme persistantes, tout objet référencé par cette variable devient alors persistant.
· Par attachement de l'objet à une structure persistante
Dans ce schéma, il existe en général un objet racine persistant. Tous les objets que l'on peut atteindre à partir de cette racine, deviennent eux mêmes persistants. On voit donc que tout objet attaché a une structure de donnée persistante devient lui-même persistant.
Requêtes
Une fois les objets stockés dans la base, il faut pouvoir les y retrouver. Il est donc necessaire que le language dispose de mécanismes permettant d'exprimer des requêtes dans la base de données. Il existe plusieurs types d'accès possibles à une base de données objet.
Accès direct et navigationnel
Ce type d'accès est intimement lié à la notion d'identifiant d'objet. Connaissant l'identifiant d'un objet, il faut pouvoir le charger le plus rapidement possible, ou être capable de se déplacer d'objet en objet en suivant les liens entre ceux-ci. En fait ce type d'accès, correspondant au fait de déréférencer des pointeurs, est uniquement interne au système, l'utilisateur n'accédant jamais directement à un objet par son identifiant. Nous verrons plus loin les mécanismes alors mis en uvre lorsque nous aborderons le problème du stockage des objets sur disque.
Accès associatif
Il s'agit alors de retrouver des objets dans la base à partir de la valeur de certains attributs de ces objets. Ce type de requête est en fait beaucoup moins utilisé que dans les bases de données relationnelles, il ne sert en effet le plus souvent qu'à obtenir des objets servant de "point d'entré", à partir desquels on naviguera ensuite dans la base.
Pour exprimer des requêtes associatives, une première possibilité consiste à les exprimer sous la forme de méthodes définie au niveau des classes des objets (méthode de classe).
C'est par exemple le cas dans Versant, ou une requête correspond à l'invocation de la méthode de classe select, avec comme argument un prédicat sur des valeurs d'attributs. Par exemple la requête "rechercher tous les pièces de classe vitale qui ont été validées" s'exprimera de la façon suivante :
// definition du predicat de selection
PAttribute("Piece::classe_")==VITALE &&
PAttribute("Piece::validation_")==true;
//execution de la requete, on recupere une liste d'identifiant d'objets
PClassObj<Piece>.select("MaBase", // nom de la base
FALSE, // non recursive (pas dans les sous-classes)
La requête est alors transmise au serveur. Celui-ci connaissant la sémantique des objets (leur schéma), les requêtes sont évaluées au niveau du serveur, évitant ainsi tout trafic inutile entre le client et le serveur.
Le grand standard en matière de langage de requête pour les bases de données relationnelles est le langage SQL, certains auteurs ont donc proposé d'étendre ce langage dans le domaine des bases de données objet.
Utilisation du langage naturel
Il peut être interessant de pouvoir exprimer une requête à la base de données sous une forme plus ou moins proche du langage naturel, soit : "je veux la liste de toutes les personnes habitant Paris dont le nom commence par la lettre T et qui ont plus de trois enfants".
Des techniques simples par utilisation de mots clefs et calcul d'un chemin entre objets à l'aide du schéma de la base de données ont permis d'obtenir des résultats très intéressants [Trigano et al 89, Trigano et al 90].
Versions
Systèmes à versions locales
Dans ce type de systèmes, on crée une nouvelle version chaque fois qu'un objet est modifié, et les versions sont représentées et stockées localement au niveau de chaque objet modifié. Le système doit alors disposer d'un mécanisme permettant d'assurer la cohérence des liens inter-objets.
Versions et identité
Dans les systèmes utilisant des versions locales, un objet et ses différentes versions sont représentés par une double structure de données. On crée un nouvel objet (avec sa propre identité) pour chaque nouvelle version. Un objet particulier souvent appelé objet générique (generic object) est chargé de représenter l'ensemble de toutes les versions de l'objet (versions set). Cet objet générique sert alors d'identifiant global (indépendamment des versions) pour l'objet. S. Zdonik [Zdonik 86a] propose par exemple d'implanter un mécanisme de versions de la façon suivante ( See Représentation des versions. ) :

Cohérence
En pratique, dans ce type de représentation, le problème de cohérence provient du fait que chaque version possède sa propre identité distincte, et qu'il faut décider comment représenter les références inter-objets ( See Versions locales et référence inter-objets. ).
· On peut pointer vers l'objet générique, mais il faut alors un mécanisme permettant de sélectionner la bonne version dans le contexte choisi (solution 1).
· On peut aussi pointer directement vers une version particulière, mais il faut alors modifier ou transférer le lien lorsque l'on crée une nouvelle version (solution 2).
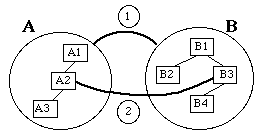
Versions locales et référence inter-objets.
Dans de nombreux cas, les objets possèdent de nombreux liens entre eux. La notion d'objet composé est un bon exemple de relation liant un objet à d'autres objets représentant ces différents composants. Lorsque l'on modifie l'un des composants d'un tel objet (et donc que l'on crée une nouvelle version de ce composant), on doit créer une nouvelle version de tous les objets intermédiaires contenant ce composant de façon directe ou indirecte. Zdonik dit alors que les modifications percolent dans l'arbre de composition.
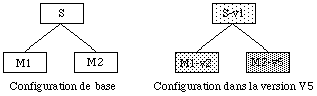
Pour illustrer ce phénomène, prenons l'exemple suivant : un système S contient les modules M1 et M2, le module M1 contient les procédures P1 et P2, le module M2 contient les procédures P3 et P4.
Si la procédure P1 est modifiée, on en crée une nouvelle version P1-v2. Comme P1 a changé, le module M1 contient maintenant une nouvelle procédure, c'est donc qu'il a lui aussi changé, on doit donc en créer une nouvelle version M1-v2. De la même façon on doit également créer une nouvelle version S-v2 du système S.
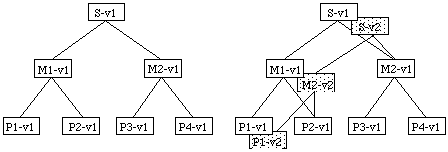
Percolation des versions.
Le mécanisme de percolation devient encore plus complexe si l'on peut créer plusieurs versions alternatives d'un même composant.
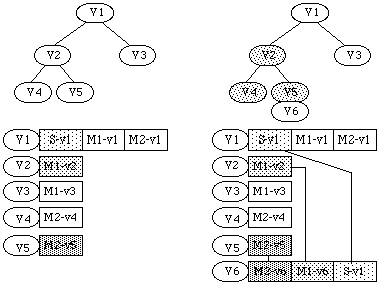
Reprenons notre exemple et supposons que l'on crée deux alternatives M1-v2a et M1-v2b du module M1 On doit alors créer aussi deux alternatives S-v2a et S-v2b du système S contenant M1. Si ensuite on décide également de créer deux alternatives M2-v2a et M2-v2b du module M2, on devra alors créer quatre alternatives S-v3a, S-v3b, S-v3c et S-v3d pour le système S (voir See Multiplication des versions par percolation. ). On risque alors rapidement une explosion combinatoire du nombre de versions.
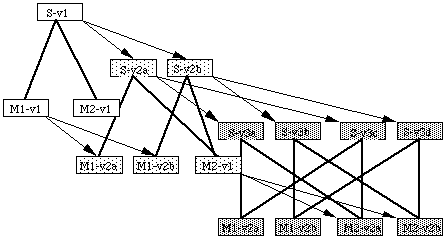
Multiplication des versions par percolation.
La propagation ou percolation de versions présente deux grands inconvénients : elle peut être très coûteuse lorsque l'on doit faire de la propagation le long de nombreux liens, elle peut également conduire à des situations ambiguës [Zdonik 86a].
Pour éviter tous ces problèmes, plusieurs solutions ont été proposées:
- limiter le nombre d'objets pouvant être versionnés, on fera alors la différence entre des objets versionnables et des objets non versionnables.
- ne pas propager des modification locales immédiatement, mais attendre pour grouper toutes les modifications ensemble (notion de "significant change" [Landis 86]). On utilise alors des techniques telles que celles de "pending versions" [Landis 86], ou de "flag based notification" [Chou & Kim 86].
Systèmes à versions globales
Dans cette nouvelle approche, les versions ne sont plus directement attachées aux objets, mais sont gérées de façon globale dans un graphe de versions unique. Chaque nud de ce graphe correspond alors à une version unique d'un ensemble d'objets et donc à une configuration globale de ces objets. La différence majeure avec l'approche locale est que les différentes versions d'un objet n'ont pas une identité séparée, et que les références sont résolues à l'aide du graphe global.
Versions et identité
Dans cette approche, tous les objets sont des objets génériques et ont un identifiant unique. L'historique des versions est factorisé dans le graphe de versions global ce qui permet une représentation beaucoup plus compacte. Ce graphe global permet par un mécanisme de type héritage de déduire la valeur d'un objet pour une version donnée. Quand un objet n'a pas été modifié dans une version particulière, sa valeur peut être retrouvée en cherchant dans le graphe global la dernière version ancêtre de la version courante pour laquelle on a stocké la valeur de l'objet.
Reprenons l'exemple précédant d'un système S constitué de deux modules M1 et M2 (donc V1={M1-v1, M2-v2}. On va créer deux versions alternatives du module M1 : une version M1-v2 que l'on va stocker dans la version 2 de la base de données (V2={M1-v2}, et M1-v3 pour la version 3 (V3={M1-v3}. Chaque état de la base de données ne contient alors que les objets que l'on a réellement modifiés.
A partir de l'état V2, on va créer deux nouvelles alternatives (V4 et V5) du système en modifiant cette fois ci le module M2. On aura donc V4={M2-v4} et V5={M2-v5}. Parallèlement aux modifications des objets et donc à la mise à jours de la base de données, on construit le graphe global des versions ( See Gestion des versions par graphe global. ).
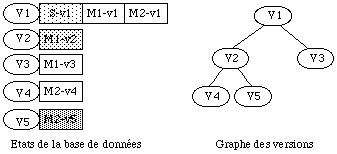
Gestion des versions par graphe global.
En utilisant le graphe global des versions, et les différents états stockés, il est très facile de reconstruire une configuration donnée. Supposons par exemple que l'on souhaite retrouver l'état du système S dans la configuration V5.
A partir de l'état V5 de la base, on recherche la valeur du système S. Ne trouvant pas de valeur dans V5, on remonte dans le graphe global de version vers V2 puis finalement vers V1 pour trouver une valeur de S. On voit alors que S est constitué des deux modules M1 et M2. De même, on va rechercher les valeurs de M1 et M2 dans la base à l'aide du graphe global. On trouvera M1 dans V2, et M2 dans V5. On obtiendra finalement la configuration V5={S-v1, M1-v2, M2-v5}.
Versions du Schéma
Jusqu'à présent, nous avons essentiellement considéré la gestion des versions des objets (des instances) stockés dans la base de données. Il nous faut maintenant envisager les possibles changements dans le schéma (les classes) décrivant les objets de la base. En effet, lorsque l'on modifie une classe, les anciennes instances de celle-ci stockées dans la base de données risquent d'être incohérentes avec la nouvelle définition de cette classe. Dans ce cas, il faut également stocker les différentes versions du schéma dans la base de données.
Dans le cas de bases de données multi-niveaux, lorsque l'on transfère un objet d'une base à une autre, il est également nécessaire de transférer la version du schéma associé à cet objet vers la seconde base si le schéma correspondant n'y existe pas.
Etats
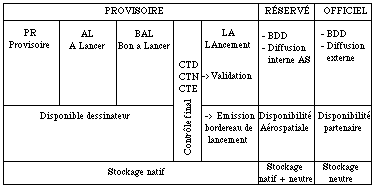
Nous avons vu dans le See REPRESENTATION DES CONNAISSANCES que la notion d'états est très importante dans le domaine de l'ingénierie. Nous allons présenter ici un exemple de base de donnée d'ingénierie (la base GILDA [Vergne 90]) qui implante une gestion des états. La base est principalement structurée en 3 états.
Un état provisoire
Cet état est uniquement accessible par le concepteur, il permet d'effectuer des sauvegardes sur un dossier au cours de son élaboration. Cet état provisoire est lui-même subdivisé en quatre sous-états qui correspondent chacun à différentes phases de test et de contrôles de validation.
La validation finale comprend plusieurs phases de contrôle : Le Contrôle Technique Dessin (CTD), le Contrôle Technique Nomenclature (CTN), et le Contrôle Technique ENC (CTE).
Un état Réservé
Cet état est utilisé pour stocker des dossiers validés pour la fabrication, mais parfois encore incomplets (traduction non réalisée par exemple). Les dossiers sont alors accessibles par les usines d'Aérospatiale.
Gestion de la persistance
Une base de donnée se doit d'assurer un stockage persistent et stable des données.
Une donnée est dite persistante si elle reste accessible après la terminaison du processus qui lui a donné naissance.
Une donnée est dite stable si elle peut résister a une défaillance du programme (process failure), une défaillance système (system failure), ou une défaillance du média de stockage (media failure).
Cette persistence et cette stabilité nessessitent de mettre en uvre des mécanismes de stockage et de reprise sur panne (recovery), que nous allons maintenant aborder. Il existe en effet plusieurs types d'approches possibles suivant le domaine de compétence et la culture du concepteur :
· Une approche type base de données où l'on considère les objets comme des enregistrements. Les objets et les attributs sont en général fortement typés, et souvent de taille plus ou moins fixe. Exemples : O2 et Vbase.
· Une approche type IA où il existe déjà une structure complexe des objets en mémoire. Dans ce cas les objets ont le plus souvent deux formats différents : un format temporaire de travail en mémoire et un format permanent de stockage sur disque. Exemples : GEMSTONE, GBASE, ORION.
Architecture générale
La technique la plus employée consiste en général à implanter une base de données objet en la séparant en deux grands modules : Un module de stockage de bas niveau, et un interpréteur de plus haut niveau.
Le module de stockage ou gérant d'objets, est chargé des tâches de plus bas niveau : transferts des objets entre la mémoire et les disques, gestion des buffers, gestion au plus bas niveau des mécanismes de transaction, de gestion des accès concurrents, et de reprise sur incident.
L'interpréteur est quant à lui chargé des interactions de l'utilisateur avec la base de données. C'est lui qui transforme les données manipulées par le module de stockage, en des objets structurés utilisables directement par l'utilisateur.
Un des principaux choix d'architecture à faire, est alors de décider où placer la séparation entre le module de stockage, et l'interpréteur; c'est-à-dire en fait de savoir ce que le module de stockage doit savoir sur la structure interne et la sémantique des objets qu'il manipule. Certains modules de stockage voient uniquement les objets comme des chaînes d'octets sans aucune sémantique. D'autres possèdent plus d'information, et par exemple connaissent la classe des objets.
Architecture client-serveur
Dans une architecture client/serveur, un des problèmes à résoudre est de minimiser la quantité de données échangées sur le réseau entre le client et le serveur. Une architecture simple consiste donc d'implanter le module de stockage sur le serveur, et l'interpréteur sur le client. Dans ce cas, le manque de sémantique connu par le gérant d'objet risque d'entraîner des échanges de données très importants entre le client et le serveur.
Il reste alors à choisir la granularité de l'implantation : les opérations élémentaires pourront alors porter soit sur une page, un objet, un groupe d'objet, un segment. Ce choit de la granularité pourra avoir des répercutions sensible sur les performances. Elle porte aussi bien sur les opérations de lecture/écriture disque, que sur les transferts entre client et serveur, ou les opérations de verrouillage.
Serveur de pages
Le choix d'une granularité au niveau de la page disque conduit à un premier type d'architecture, nommée serveur de pages, qui est représentée à la See Architecture d'un serveur de pages . Ce type d'architecture permet en général de bénéficier de mécanismes de bas niveau offert par le système d'exploitation pour l'accès et le verrouillage de pages au niveau disque.
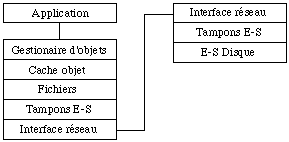
Serveur d'objets
Le choix d'une granularité au niveau de l'objet ou même de groupe d'objets (segments) conduit à un second type d'architecture de type serveur d'objets ( See Architecture d'un serveur d'objets ).
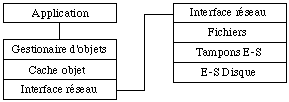
Importance de la taille sur l'architecture
Les systèmes distribués simplifient les communications et les partages de données entre utilisateurs. Plus la taille du système augmente, plus il devient une ressource indispensable à ces utilisateurs. L'accès au système devient alors une nécessité vitale pour les utilisateurs. Les utilisateurs dépendant de plus en plus de ce système distribué, la disponibilité des données devient alors un point fondamental. De même que la taille est un paramètre de premier ordre dans la structuration d'un programme, la taille et donc la complexité est un paramètre fondamental dans l'architecture d'un système distribué [Satyanarayanan 92]. Celle-ci dépend entre autres des paramètres suivants :
- nombre de noeuds dans le système
- nombre d'utilisateurs simultanés
- nombre de sous groupes ou d'organisations dans le système
Un système distribué ayant une grande durée de vie sera inévitablement confronté à des problèmes de croissance. Il faut donc prendre en compte ce problème dès le départ et choisir une architecture en conséquence.
Un système distribué doit pouvoir être tolérant aux pannes des serveurs et du réseau. Cette résistance aux pannes peut être réalisée par la réplication des données. Un système distribué de grande taille doit pouvoir conserver de bonnes performances. Une technique permettant de conserver de bonnes performances consiste à utiliser un système de cache. En implantant un système de cache, on doit prendre 3 grandes décisions :
- comment maintenir la cohérence du cache ?
- quand propager les modifications ?
Les meilleures performances sont en général obtenues en situant le cache sur le disque local du client. Cette aptitude à cacher les données au niveau du client, est un des facteurs qui contribue le plus à assurer une croissance sans perte de performance (scalabilité) dans un système distribué.
Plusieurs solutions sont possibles pour maintenir la validité du cache :
Une première approche consiste pour le client à valider un objet caché après chaque utilisation de cet objet. Cette stratégie résulte en au moins une interaction avec le serveur pour chaque ouverture de fichier.
Une autre solution est que quand un client cache un objet, le serveur fait la promesse (appelée "callback ou token") qu'il notifiera le client avant d'autoriser un autre client à modifier l'objet fourni.
Un autre choix important est celui de la granularité des transferts de donnée entre le client et le serveur. On peut retenir certains principes généraux.
· Lorsque cela est possible, il est toujours préférable de faire faire les opérations par le client. Il faut utiliser des caches lorsque c'est possible.
· Il est intéressant d'exploiter la sémantique des objets manipulés.
· Il faut chercher à minimiser les besoins et donc la recherche d'information sur toute l'étendue du système (system-wide data).
Gestion des objets en mémoire
Il existe deux niveaux d'implantation des identifiants d'objets en mémoire.
Représentation par des pointeurs
Ces systèmes ont été imaginés en faisant la constatation que dans de nombreux programmes, une grande partie des données est sous la forme de pointeurs vers d'autres données. Ces pointeurs vers les objets servent de référence, et sont passés comme paramètres dans les procédures. On souhaiterait donc pouvoir stocker sur disque les objets tels qu'ils sont en mémoire, en conservant directement la notion de pointeurs entre objets.
Systèmes basés sur la sauvegarde d'images mémoire.
Ce type de mécanisme est notamment utilisé dans certains systèmes LISP. On maîtrise le système d'allocation mémoire, il est alors possible de gérer certaines zones mémoire comme étant volatiles et d'autres persistantes. On gère alors la mémoire par segments, dans lesquels on gère l'allocation des objets. Il est alors possible d'écrire les objets sur disque en transformant l'adresse d'un objet en un déplacement par rapport à sa position dans le segment.
Ce type d'approche n'est en général utilisé que dans des environnements mono-utilisateur, et on ne dispose en général pas de mécanisme de reprise sur panne.
Système de gestion de mémoire virtuelle persistante (ex : ObjectStore)
Dans ce type de systèmes, on étend la notion de mémoire virtuelle en définissant un modèle abstrait et uniforme de mémoire. Ce modèle définit une architecture d'un système de stockage qui traite de façon uniforme les objets volatiles et les objets persistants. Dans ce modèle, le processeur voit la mémoire comme un ensemble d'objets ou blocs de taille variable, interconnectés par des pointeurs. Chaque objet est constitué d'un ou de plusieurs mots mémoire qui sont stocké à des adresses virtuelles consécutives. Les pointeurs sont eux-mêmes sous la forme d'adresses virtuelles.
Dans cette abstraction, on utilise la notion de racine persistante (persistant root), qui est un objet particulier, situé à une adresse virtuelle et une adresse disque fixée. Tous les objets que l'on peut atteindre à partir de cette racine persistante sont eux-mêmes persistants. Cette racine persistante doit pouvoir survivre à un arrêt ou incident système. Tous les types d'objets (nombre, chaîne de caractère, liste, procédure, etc....) peuvent être rendus persistants à partir du moment où ils sont dans la fermeture transitive de la racine persistante.
Les registres du processeur (registre interne + piles), définissent eux une racine volatile pour les objets. Ces registres ne survivent pas à un arrêt ou erreur système. Tous les objets qui sont dans la fermeture transitive de la racine volatile, mais pas dans la fermeture transitive de la racine permanente sont dit volatils.
Du point de vue du processeur, les objets volatils et les objets persistants ne sont pas distinguables. L'utilisateur n'a aucune différence à faire dans le traitement des objets volatils ou des objets persistants. Il lui suffit de les manipuler par leur pointeur.
On voit donc que l'accès à un objet par un pointeur sera le même, qu'il soit persistant ou non, d'où une grande efficacité.
Le gestionnaire d'objets persistants est implanté au-dessus du mécanisme de mémoire virtuelle uniforme. Son rôle est de définir l'accès à la racine persistante de manière à en assurer l'intégrité. On a alors l'architecture suivante ( See Architecture d'un système de mémoire virtuelle persistante. ).
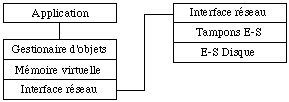
Représentation par identifiants d'objets
On a alors obligatoirement un niveau d'indirection à chaque accès au contenu d'un objet.
Une référence à objet repéré par son identifiant (G-BASE::OID = 223) mais non chargé en mémoire (champ G-BASE::STATUS = nil)
#<Structure GBASE-KEY 20BA5CE>
Lorsque l'on cherche à accéder à un objet, trois cas peuvent se présenter :
1 - la référence contient déjà un pointeur vers l'objet
--> c'est bon, on peut accéder à l'objet
2 - la référence est vide, on va chercher dans un cache pour voir si l'on n'a pas déjà lu l'objet par ailleurs. Si l'on trouve l'objet dans le cache, on met à jour la référence et l'on est ramené au cas précédent.
3 - la référence est vide et on ne trouve pas l'objet dans le cache. On est alors obligé d'aller lire l'objet sur disque. On met à jour le cache et la référence, et on est ramené au premier cas.
Classiquement, le cache est implanté sous forme d'une table de hachage ayant comme clef d'accès l'identifiant de l'objet.
Après lecture dans la base de données, le champ G-BASE::STATUS pointe vers le contenu de l'objet
#<Structure GBASE-KEY 20BA5CE>
[1: G-BASE::STATUS] #<Simple-Vector T 15 20BA5DE>
Une autre méthode assez élégante est basée sur le fait que sur les machines RISC modernes, les objets en mémoire sont le plus souvent alignés sur une frontière de mot (en général 32 bits), il est alors possible d'utiliser les deux bits de poids faible (bits de tag) pour marquer les pointeurs. Cette technique a notamment été utilisée dans l'implantation de système LISP sur des processeurs de type SPARC.
Il est possible d'utiliser ces bits de tag pour faire la discrimination entre un identifiant d'objet sur disque, et un identifiant d'objet en mémoire sous la forme d'un pointeur. En forçant le bit de poids faible à 1, on désignera un identifiant d'objet sur disque, alors qu'un bit de poids faible à 0 (donc représentant une adresse alignée sur une frontière de mot) désignera un pointeur mémoire valide. L'accès à un objet déjà en mémoire se réduira alors à un simple test de bit (pour vérifier que l'on a bien un pointeur valide) suivi de l'accès au pointeur lui même. On trouve un exemple de cette technique de gestion d'objets persistants dans la version 2.6 d'InterViews.
Gestion de la mémoire
Le volume des objets manipulés lors d'une session peut être très supérieur à la taille de la mémoire virtuelle du système, d'autre part, les différentes manipulations peuvent donner naissance à des objets non référencés. Il faut donc disposer d'un mécanisme permettant de libérer de la mémoire en éliminant les objets non référencés et déchargeant certains autres objets en base de données.
Les mécanismes à mettre en uvre sont alors très proches de ceux utilisés pour gérer la mémoire virtuelle : "garbage collecting" [Wilson & Moher 89] et "swapping" (on parle alors de défaut d'objet qui est l'équivalent du défaut de page pour la mémoire virtuelle).
Gestion des objets sur disque
Format et codage
Il faut pouvoir être capable de passer d'une représentation des objets en mémoire qui peut être complexe, en une représentation stockable sur disque. Cela nécessite de définir une procédure de "mise à plat" des objets ( See Formatage des objets sur disque (d'après Barthès). ).
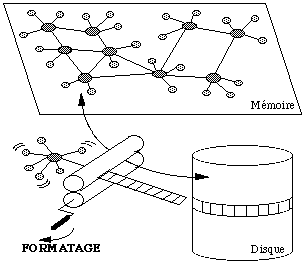
Formatage des objets sur disque (d'après Barthès).
Il est important que le volume des données sur disque ne soit pas beaucoup plus important que le volume des données en mémoire. En effet dans certains systèmes, le passage sur disque se traduit parfois par une importante augmentation de l'espace de stockage nécessaire : 1 Méga-octets en mémoire pouvant alors nécessiter plusieurs Méga-octets sur disque. Des expériences sur Gbase [Anota & Barthès 88] ont montré qu'une représentation sur disque compacte permettait d'améliorer les performances en minimisant les lectures disque et les transferts client / serveur.
Objets volumineux
Lorsque l'on utilise une base de données "classique" pour stocker les objets, ceux-ci peuvent parfois être de dimension supérieure à la taille maximale des enregistrements gérés par la base. Il est alors nécessaire de découper les objets en segments pour pouvoir les stocker. D'autre part, même si la base permet de stocker des objets de taille quelconque, il peut être intéressant de différencier les méthodes de stockage selon la taille et la nature des objets.
Regroupement des objets (clustering)
Afin d'optimiser les accès à la base de données, il est souhaitable de pouvoir stocker de façon contigue sur disque des objets en relation mutuelle (cas notamment des objets composites) [Banerjee et al 88]. Le but est de pouvoir manipuler un objet composé comme une seule et unique entité, tant du point de vue du stockage et des opérations de lecture/écriture, que du point de vue contrôle et maintient de la cohérence. C'est un point qui peut avoir un impact très important sur les performances.
Si l'on tient à assurer l'indépendance physique des données, le clustering devrait pouvoir se faire a tout moment et pas seulement à la création des objets. Le clustering doit être vu comme une opération de gestion et d'optimisation des performances de la base, mais ne pas être visible au niveau de l'utilisateur ou des programmes applicatifs. C'est-à-dire que l'utilisateur ne devrait pas avoir à se préoccuper de savoir dans quel segment les données ont été rangées. Ces opérations seraient réservées à l'administrateur de la base de données, qui en fonction de l'historique de l'utilisation des objets, est le mieux à même de faire les regroupements intéressants.
Un cas particulier important de clustering intervient dans tous les systèmes possédant une forte structuration spatiale (Cartographie, C.A.O.). Dans ce type de systèmes, une des opérations les plus courantes consiste à afficher dans une fenêtre une vue de la base de données. En cartographie : on veut afficher certains éléments (routes, habitations, type de terrain, courbes de niveaux, etc....) couvrant la région que l'on désire afficher à l'écran. On veut donc effectuer une espèce de "cliping" sur la base de donnée. On sélectionne les éléments à afficher, à la fois par leurs coordonnés et par leur nature (route, habitations)
Le problème est qu'on ne veut pas avoir à explorer toute la base de données, avoir à charger tous les objets pour ensuite se rendre compte qu'ils ne se situent pas dans la zone que l'on désire afficher.
Pour résoudre ce problème, il y a deux grandes techniques : soit grouper les objets voisins ensembles dès le départ, soit utiliser des index spatiaux dont nous parlerons lorsque nous aborderons le problème général des index.
Compactage du disque
Si le modèle utilisé n'impose pas de restriction sur la taille et le type des attributs des objets, ceux-ci auront donc une taille variable. Il sera donc nécessaire de gérer dynamiquement l'espace disque et de prévoir un mécanisme périodique de recompactage (garbage collection) de cet espace.
· Si l'on gère les versions, il faut définir un "garbage collector de versions".
· Si la base doit tourner en permanence, il faut un système de recompactage incrémental.
Dans tous les cas, il est fondamental d'être capable de reconstruire les fichiers de la base en cas de panne ("crash") du système lors du recompactage de celle-ci.
Indexation
Si on veut pouvoir retrouver rapidement des objets dans la base, il faut être capable d'indexer certains attributs de ces objets.
Indexation par nom
Un premier type d'indexation très utile est de pouvoir nommer certains objets dans la base de données [Merrow & Laursen 87].
· Le nom d'un objet sert à la fois de point d'entrée pour retrouver l'objet et de pointeur logique pour des inter-références entre objets
· Le nom d'un objet peut aussi servir a partitionner l'espace des objets. Une application peut seulement utiliser les objets dont elle peut avoir le nom ou a travers les références à d'autres objets.
Il peut alors être intéressant d'organiser l'espace des noms de façon hiérarchique. Le nom d'un objet sera alors composé de 2 parties : une qui identifie une partition, l'autre qui identifie de façon unique l'objet dans la partition. On retrouve cette idée dans le système des packages en Common Lisp.
Indexation par classe
Un des critères de recherche le plus fréquent étant le type de l'objet (sa classe), il est courant que les objets soit indexés par leur classe.
Indexation spatiale
Un certain nombre d'applications telles que la cartographie, les systèmes d'informations géographiques, les systèmes de conception assistée par ordinateur (C.A.O.), sont caractérisées entre autres par des données organisées de façon spatiale. Pour ce types de données, il est nécessaire de disposer de facilitées permettant d'indexer et de repérer des objets à partir de leur localisation dans l'espace [Orenstein 86].
En C.A.O. on veut par exemple pouvoir être capable de trouver les objets proches les uns des autres. On veut pouvoir exprimer des requêtes telles que : "je veux la liste des câbles passant près de ce moteur".
En cartographie, on veut afficher certains éléments (routes, type de terrain, courbes de niveaux, etc....) couvrant la région que l'on désire visualiser. On veut donc effectuer une espèce de "cliping" sur la base de donnée, sans avoir à explorer toute la base, charger les objets pour ensuite se rendre compte qu'ils ne se situent pas dans la zone que l'on désire afficher.
La majorité des méthodes d'indexation spatiales sont basée sur le partitionnement de l'espace en sous-espaces discrets [Orenstein 86]. On utilise soit une grille, soit un processus de décomposition hiérarchique (on utilise par exemple les quad-tree pour des images).
Reprise sur panne
Les systèmes de base de données doivent utiliser un système de reprise sur panne (recovery system) pour assurer l'intégrité des données après une défaillance du programme ou du système. Nous allons voir quel sont les différentes techniques utilisables.
Les différents types de pannes
Une panne peut avoir différentes causes : erreur humaine, erreur de programmation, dysfonctionnement du matériel. On distingue en général plusieurs niveaux de pannes [Gardarin 92].
· Erreur au niveau d'une action
Une telle erreur survient lorsqu'une commande est mal exécutée. Cette erreur est alors détectée par le système qui déclenche une exception ou renvoie un code d'erreur. Cette exception peut alors être traitée et permettre de continuer la transaction en cours.
Une telle erreur survient lorsqu'une transaction ne peut s'exécuter correctement (erreur de programmation, verrou mortel). Les effets de la transaction doivent alors être annulés (rollback).
Une telle panne peut être due soit à une erreur grave dans le SGBD ou dans le système d'exploitation, soit dans une panne machine. Dans tous les cas, cela ce traduit par l'arrêt du système. Toutes les transactions en cours (en mémoire) sont perdues. Par contre, la mémoire secondaire n'est pas affectée et les transactions déjà validées sont récupérées après redémarrage du système.
Une telle panne peut être due soit à une erreur grave induisant de mauvaises écritures sur disque, soit à une panne matérielle endommageant le support physique. Si l'on ne dispose pas d'une autre copie des données celles-ci sont alors irrémédiablement perdues.
Mécanismes de reprise sur panne
Utilisation de journaux
La méthode la plus classique permettant de faire une reprise sur panne est l'utilisation de journaux. On distingue habituellement deux types de journaux.
Journal avant (before image) : fichier système contenant les valeurs des objets avant modification de ces objets.
Journal après (after image) : fichier système contenant les valeurs des objets après modification de ceux-ci.
La See Utilisation des journaux. illustre l'utilisation de tels journaux.
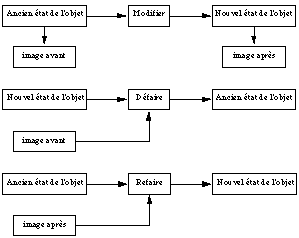
Versions et reprise sur incident
L'existence d'un mécanisme de gestion de versions peut grandement aider à faire de la reprise sur incident dans une base de données orientée objet. En effet, un système permettant de gérer des versions n'a pas besoin d'utiliser des journaux, puisque les anciennes valeurs des objets (leurs anciennes versions) sont toujours présentes sur disque. Nous verrons qu'un tel mécanisme est par exemple utilisé dans Gbase.
Points de reprise (save points)
L'idée est de pouvoir déclarer et marquer un état bien déterminé d'une transaction en cours, afin de pouvoir le cas échéant revenir à cet état en cas de problème. C'est un niveau de reprise plus fin que la transaction mais très important dans les cas de transactions longues.
Sauvegarde (backup)
Si les deux techniques précédentes permettent de faire une reprise lors d'une panne système, elles n'assurent par contre aucune protection contre une panne de média.
Pour se protéger contre une telle panne, la solution la plus couramment utilisée consiste à faire périodiquement des sauvegardes des données de la base sur un autre support physique (backup), ou de dupliquer systématiquement les informations de façon redondante (réplication) sur plusieurs média physiques, par exemple sur des disques différents.
Contrôle de concurrence
Introduction
Le contrôle de concurrence a pour objet de synchroniser les accès à une base de données partagée par plusieurs utilisateurs. Il doit détecter et gérer les conflits qui surviennent entre les différents utilisateurs lorsqu'ils accèdent simultanément aux mêmes données.
Disposer d'un mécanisme de contrôle de concurrence est une nécessité absolue pour une base de données multi-utilisateurs.
Le système de contrôle de concurrence doit permettre de satisfaire les deux points suivants :
- Assurer la cohérence des données.
- Assurer un niveau de parallélisme élevé.
Dans le cas idéal, tout doit se passer pour l'utilisateur comme s'il était seul à accéder à la base. Une base de données est sans cesse modifiée, et évolue normalement d'états cohérents en états cohérents des données par suite des opérations des utilisateurs. Cette notion de cohérence des données de la base est fondamentale. La cohérence des données est caractérisée par le respect de contraintes d'intégrité par l'ensemble des données.
Définitions
Transaction
Dans le monde des bases de données, un concept fondamental est celui de transaction. L'utilisation de transactions est l'outil permettant d'assurer de façon cohérente l'accès concurrent de plusieurs utilisateurs à une même base de données. Une transaction est l'unité de travail la plus élémentaire sur une base de donnée.
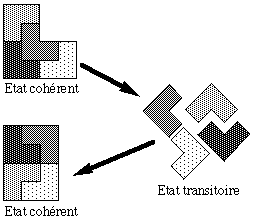
Notion de transaction.
Une transaction est la suite d'opérations qui permet de passer d'un état cohérent à un autre état cohérent de la base de données de façon atomique et récupérable.
Les principales propriétés pouvant être associées à une transaction sont : l'atomicité, la consistence, l'isolation et la durabilité (règles ACID).
Atomicité
Une transaction est atomique si son effet sur la base de données peut être considéré comme un tout unique. L'atomicité garantit qu'une transaction est soit complètement exécutée, soit ne l'est pas du tout.
Consistence
Une transaction doit veiller au respect des contraintes d'intégrités sur les données manipulées, et doit soit laisser la base dans un nouvel état cohérent, soit revenir à l'état cohérent précédent (critère d'atomicité). Le seul moment ou les données peuvent être incohérentes se situe durant l'exécution de la transaction, mais ces données incohérentes ne doivent alors être visibles que de cette seule transaction (critère d'isolation).
Opération
Une transaction est définie par une suite d'unités de traitements élémentaires appelés opérations.
Une opération est totalement indivisible, c'est la plus petite unité de traitement exécutable. Les opérations élémentaires les plus simples sont Lire (read) ou Ecrire (write) dans la base de données.
Différents types de transactions
Transactions imbriquées
Ce type de transaction intervient dans des applications dans lesquelles une opération comprend l'exécution de plusieurs transactions élémentaires sur des bases de données différentes. Chaque transaction élémentaire reste courte, mais l'ensemble de ces transactions pouvant avoir lieu durant plusieurs journées de travail, l'opération n'est finalement validée que si l'ensemble des transactions élémentaires l'est aussi.
Un exemple représentatif de ce type de transaction est l'établissement par une agence de voyage, d'un séjour comprenant des réservations de billets d'avions, d'une chambre d'hôtel et la location d'une voiture. L'annulation du séjour nécessitera de défaire toutes les réservations élémentaires.
Ce type d'application peut être modélisée comme étant constituée d'une transaction "chapeau" de longue durée qui comprend plusieurs transactions courtes de plus bas niveau. L'idée étant qu'au moment de la validation (commit) de chacune de ces transactions de bas niveau les ressources utilisées sont libérées, et l'effet de ces transactions devient perceptible par les autres utilisateurs, d'où une bonne concurrence dans le système. Bien entendu un abandon (abort) au niveau applicatif, c'est-à-dire ici l'annulation du séjour, doit se traduire par l'exécution de transactions de bas niveau en vue de défaire le travail effectué précédemment par ces mêmes transactions.
Transactions longues (transactions de conception)
Les transactions dans des environnements de conception peuvent manipuler un grand nombre d'objets complexes et peuvent avoir lieu sur de longues périodes de temps, de l'ordre de plusieurs jours. D'autre part, lorsque l'on conçoit un objet physique, il arrive souvent que l'on désire évaluer parallèlement plusieurs hypothèses. Il est donc nécessaire de disposer d'un mécanisme de gestion de versions.

L'utilisation de ce mécanisme de check-out/check-in suppose la mise en place de verrous persistants (verrous pouvant survivre à une panne système) pour verrouiller les objets jusqu'au check-in.
Ce mécanisme de recopie dans une base locale privée, puis rebasculement après validation dans une base globale partagée peut s'envisager seul, mais il devient encore plus intéressant s'il est couplé à un mécanisme de gestion de versions. Il devient alors possible de garder plusieurs versions des données dans la base globale, assurant ainsi la possibilité de revenir à une version antérieure en cas de problème. Cela permet également de tester différentes hypothèses au niveau d'une base locale privée.
Exemples de problèmes d'accès concurrents.
Nous avons vu que le rôle du contrôle de concurrence est d'empêcher toutes interférences entre utilisateurs accédant simultanément à une même base de données. Pour illustrer les problèmes qui peuvent survenir, nous allons donner deux exemples de ce qui peut se passer si l'on ne dispose pas d'un bon mécanisme de contrôle de concurrence.
Ces deux exemples concernent des transferts de fond entre comptes bancaires, domaine ou les problèmes deviennent immédiatement visibles.
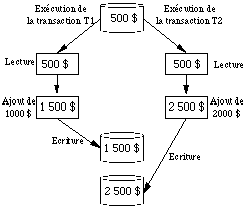
Mise à jours perdue (lost update)
Ce premier exemple montre l'effet de la mise à jour d'un même compte par deux personnes de façon simultanée. Les deux personnes consultent le solde du compte, calculent la valeur du nouveau solde après leurs dépôts respectifs et enfin écrivent le nouveau résultat dans la base de donnée ( See Un exemple de mise à jour perdue (lost update) ).
En l'absence de mécanisme de contrôle de concurrence, on voit que l'effet global des deux opérations est incorrect. Les deux utilisateurs ont voulu déposer de l'argent sur le compte, mais la base ne reflète le résultat que d'une seule opération : un seul des dépôts a été pris en compte, l'autre a été perdu.
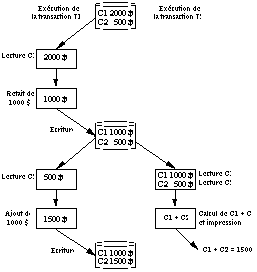
Lecture incohérente (inconsistant read)
Ce deuxième exemple concerne un premier utilisateur qui transfère de l'argent d'un compte C1 a un compte C2. Simultanément, une autre personne désire connaître le solde cumulé de ces deux comptes ( See Un exemple de lecture inconsistante (inconsistent read) ). Ici, à la fin des opérations, le contenu de la base de donnée est bien correct, le problème vient du fait que le second utilisateur calcule et affiche la somme des deux comptes alors que ceux-ci sont en train d'être manipulé par le premier utilisateur. Il obtient donc une vue (la somme des deux comptes) qui n'est pas correcte.
Critères d'exécution sans conflits
Sérialisation
L'exécution de plusieurs transactions sera sérialisable si le résultat global de ces transactions sur la base de données est le même, que ces transactions soit exécutées de façon concurrentes (exécution entrelacée), ou quelles soit exécutées dans un ordre quelconque les unes après les autres (exécution en série).
Les exemples vus précédemment ne sont pas sérialisables car les résultats obtenus sont différents si l'on exécute les transactions en série, ou si on les exécute de façon concurrentes.
Supposons qu'au départ, X ait la valeur 500.
Exécution 1 (exécution en série T1 puis T2)
Exécution 2 (exécution en série T2 puis T1)
Exécution 3 (exécution concurrente)
Nous voyons que le résultat de l'exécution concurrente des deux transactions n'est pas le même que celui de leur exécution en série. En fait on remarque que la transaction T2 a écrasé le résultat de la transaction T1.
L'exécution sérialisable des transactions est donc un critère de conservation de la cohérence de la base de données. Parmi les différentes exécutions concurrentes possibles de plusieurs transactions, certaines seront sérialisables et d'autres pas. Le rôle du mécanisme de contrôle de concurrence sera donc de ne permettre que des exécutions sérialisables de transactions.
Nous avons vu avec notre exemple qu'une exécution n'était pas sérialisable lorsqu'il se créait des dépendances entre deux transactions sur l'utilisation d'une ressource commune. Pour détecter de telles dépendances, et par la même prouver qu'une exécution est sérialisable, il existe un outil mathématique appelé graphe de précédence.
Graphe de Précédence
Deux opérations OPi et OPj sont dites compatibles si toute exécution de OPi suivie de OPj est équivalente (donne le même résultat) à l'exécution de OPj suivie de OPi.
Critère de sérialisation
A partir du graphe de précédence, il est possible d'établir un critère de sérialisation de la façon suivante [Papadimitriou 79] :
Une exécution concurrente de transactions est sérialisable si le graphe de précédence est sans circuits.
Niveaux de cohérence
A partir des deux opérations élémentaires que sont la lecture (read) et l'écriture (write) et des différents types de conflits entre ces deux opérations, Gray [Gray et al 76] a défini trois degrés de cohérences sur les données.
Degré 1 : respect du conflit W --> W
évite les pertes d'opérations (Lost-Update)
Degré 2 : respect du conflit W --> R
évite l'observation d'incohérences (Dirty Read)
Degré 3 : respect du conflit R --> W
évite la non-reproductibilité des données (Unrepeatable Reads)
Une transaction est dite de degré i si les conflits de degré i sont pris en compte dans le graphe de précédence. Le degré trois correspond au critère de sérialisation encore appelé critère d'isolation [Taylor 86].
Algorithmes de contrôle de concurrence
Le but des algorithmes de contrôle de concurrence va donc viser à empêcher toute exécution non sérialisable des transactions.
Verrouillage
Le mécanisme le plus classique de maintient de la cohérence en environnement multi-utilisateurs est le mécanisme dit de verrouillage à deux phases (two phases lock ).
Une transaction deux-phases doit verrouiller tous les objets sur lesquelles elle travaille (première phase de verrouillage) avant de commencer à déverrouiller (seconde phase de libération des verrous posés). Ce système fait que la transaction passe par un état de verrouillage maximal où tous les objets accédés sont verrouillés.
Les algorithmes de verrouillage présentent tous le risque d'apparition d'une situation d'interblocage entre transactions concurrentes. Un interblocage ou verrou mortel (deadlock) intervient lorsque deux transactions ont posé des verrous sur certains objets et sont mutuellement bloquées en attente sur ces mêmes objets.
Soit une transaction T1 qui a verrouillé un objet A et attend le verrouillage d'un autre objet B. Une seconde transaction T2 a déjà posé un verrou sur cet objet B et attend elle-même d'obtenir un verrou sur l'objet A. Chacune des transactions est en attente d'une ressource déjà verrouillée par l'autre. Il y a alors une situation de verrou mortel. La figure suivante, tirée de [Franquin & Jidehem 77], illustre parfaitement de façon humoristique ce type de problème ( See Un exemple de verrouillage mortel (dead lock). ).

Un exemple de verrouillage mortel (dead lock).
Il existe trois façons de traiter le problème de l'apparition de verrous mortels [Howard 73].
La prévention consiste à supprimer les conditions qui rendent possibles les situations de verrou mortel. Les deux méthodes les plus utilisées, les algorithmes de DIE-WAIT et WOUND-WAIT [Rosenkrantz et al 78], utilisent un préordonnacement des transactions.
Dans l'algorithme de DIE-WAIT, quand une transaction Ti demande à verouiller un granule qui est déjà verrouillé (dans un mode incompatible) par une transaction Tj, Ti attend Tj seulement si i < j et sinon meurt (est reprise). Ainsi une transaction ne peut qu'attendre une transaction plus jeune et donc aucun circuit ne peut apparaître dans le graphe des attentes.
L'algorithme de WOUND-WAIT est symétrique du précedant. Les transaction les plus jeunes attendant les plus vielle, et les transaction les plus anciennes tuant les plus jeunes s'il y a incompatibilité.
C'est la méthode la plus couramment employée. Elle consiste appliquer un algorithme de détection de circuits sur le graphe des attentes, en éliminant successivement les sommets pendants (c'est-à-dire les transactions n'attendant le verrouillage d'aucun granule). Cette procedure fournit une liste des transactions en situation d'interblocage. Il reste ensuite a choisir une transaction à recycler. On peut par exemple choisir de tuer la transaction qui bloque le plus grand nombre d'autres transactions.
Cette methode consiste, en gérant le graphe de précédence des transactions, d'empêcher la formation de circuits sur celui-ci, soit en retardant certaines opérations, soit en forçant la reprise de transactions.
Algorithmes Avancés
Tous les algorithmes que nous venons de voir ne s'appliquent bien qu'à des transactions sérialisables et de courte durée. Plusieurs autres solutions ont été proposées.
Notification
Au lieu de verrouiller les objets auxquels on accède, et risquer ainsi de nombreux conflits d'accès, on peut vouloir seulement être prévenu de la modification d'un objet sur lequel on travaille. On peut pour cela demander qu'un objet soit marqué (notify trigger), ce qui permet d'être prévenu lorsque cet objet sera modifié de façon permanente par un autre utilisateur (cela ne résout pas le problème de savoir ce qu'il faudra faire à ce moment là).
Verrouillage sémantique
L'utilisation de langages persistants en environnement transactionnel multi-utilisateurs peut poser quelques problèmes. Dans de tels environnements, il existe en général un certain nombre de structures de données tel des catalogues ou certaines données globales partagées par tous les utilisateurs, qui sont des points chauds dans les mécanismes de contrôle de concurrence. L'accès à ces données est souvent un goulot d'étranglement pour le système. Pour résoudre ce type de problèmes, les développeurs de systèmes de gestion de base de données ont en général recour à un traitement particulier du contrôle de concurrence pour de tels types de données. Par exemple, on n'utilise des verrous que lorsqu'on accède physiquement en écriture à de telles données, et ces verrous sont immédiatement libérés [Hanson et al 91].
Les langages persistants quant à eux, utilisent en général de façon uniforme le même système de contrôle de concurrence et de reprise sur incident pour toutes les données. Il s'agit le plus souvent d'une variante du verrouillage à deux phases (two phase lock) et d'un système de journalisation. Cette uniformité du langage rend alors très difficile l'utilisation de données globales, car il se produira immanquablement à ce niveau de nombreux conflits d'accès, qui engendreront une baisse importante des performances.
Les développeurs de langages persistants devront donc apporter un soin particulier à ce problème. Une solution est de donner aux utilisateurs un accès plus fin au système de stockage pour permettre de personnaliser le mécanisme de contrôle de concurrence sur certain type de structures de données.
Utilisation de versions
Si deux utilisateurs modifient le même objet, on crée une nouvelle version différente de cet objet pour chacun des utilisateurs. Le risque est alors de voir se multiplier les versions incompatibles d'un même objet. Ceci nécessite de pouvoir fusionner les versions parallèles [Barthès 93]
Problème de la frontière des objets
Le problème est d'identifier quels objets, ou quels composants d'un objet doivent être accédés lorsque l'on manipule les données.
La technologie des bases de données actuelles est en grande partie basée sur cette hypothèse : les objets sont de relativement petite taille, et sont bien isolés les uns des autres.
Dans les bases de données conventionnelles, les objets sont simples en ce sens qu'ils ne sont logiquement rattachés qu'à un petit nombre d'autres objets, et qu'ils ne sont pas composés d'autres objets. Ils forment des enregistrements en général de petite taille aux frontières bien définies. Les objets inter-dépendents sont souvent physiquement groupés, et sont verrouillés ensembles pour assurer qu'une modification sur un objet a lieu de façon cohérente avec les autres. Les groupes d'objets étant de petite taille, il y a peu de conflits entre transactions.
Les objets utilisés en IA ou en CFAO, au contraire, sont complexes, contiennent de nombreux composants, et sont en relation avec de nombreux autres objets. Lors d'un accès, il n'est plus possible d'établir une frontière nette autour de l'objet, ni de stocker simultanément l'ensemble des objets inter-dépendants.
De même, l'application des techniques classiques de verrouillage, peut rapidement conduire à verrouiller une grande partie de la base de donnée, et à des conflits fréquents entre transactions.
Administration
Comme nous l'avons déjà vu, l'un des rôles d'un système de gestion de base de données, est d'administrer les données qui lui sont confiées, et les autorisations d'accès à celles-ci. Ce travail est en général confié à un spécialiste appelé administrateur de bases de données (DBA pour DataBase Administrator).
- Il veille à la cohérence et l'intégrité des données
- Il veille à la sécurité de la base de données
- Il permet le partage des données entre les différents utilisateurs
- Il gère et optimise le stockage physique des données
- Il optimise les performances de fonctionnement du système.
- Il garantit la pérennité des données en effectuant des sauvegardes
- Il exécute les opérations de reprise après un incident
Gestion des utilisateurs et des droits d'accès
Pour des questions de sécurité et de confidentialité, il est nécessaire de pouvoir définir quelles sont les personnes autorisées à accéder à la base de données, quelles opérations leur sont permises et sur quelles données. Il faut donc avant tout définir quels seront les sujets, c'est-à-dire quels seront les utilisateurs (personnes ou programmes), quelles seront les données sur lesquels ils agiront, et quel seront les opérations sur ces données. Là-encore se pose un problème de choix de granularité à faire au niveau des objets et des opérations.
Les autorisations doivent elles porter sur des objets (instances) individuels, ou doivent-elles porter sur toutes les instances d'une classe. Le contrôle d'accès doit-il se faire globalement sur tout un objet, ou doit-on le spécifier plus finement au niveau des attributs et des méthodes.
Pour contrôler la sécurité de la base, ainsi que de pouvoir connaître la charge de travail et être capable d'établir des statistiques, il est nécessaire de disposer d'outils d'audit.
Opération sur les bases
Création et destruction de bases
Il faut tout d'abord disposer d'outils pour pouvoir créer, et détruire une base de donnée. La majorité des bases de données fonctionnant en mode client-serveur, il faut donc être capable de démarrer et d'arrêter ce serveur.
Démarrage et arrêt
Le démarrage peut le plus souvent s'effectuer de différentes façons selon qu'il s'agisse d'un démarrage normal, ou qu'il s'agisse d'un démarrage après un crash de la base.
Pour certaines opérations lourdes de maintenance, il peut être également nécessaire de démarrer la base en mode exclusif, c'est-à-dire que la base n'est alors accessible que par le seul administrateur.
L'arrêt, lui aussi peut s'effectuer de différentes façons, le but étant normalement de perturber le moins possible le travail des utilisateurs connectés à la base. Il est donc souhaitable de permettre la fin normale des connexions établies, ou tout au moins, la fin normale des transactions déjà entamées.
On distingue généralement trois types de reprise :
- la reprise normale qui à lieu après un arrêt normal de la base
- la reprise à chaud consécutive à une panne contrôlée (erreur d'entrée sortie, interblocage,...)
- la reprise à froid après une panne non contrôlée (erreur système, problème réseau,...)
Opérations sur les données
Sauvegardes et archivage
La plupart des systèmes de gestion de base de données sont vulnérables aux incidents endommageant directement leurs supports physiques (disque magnétique). Pour se protéger contre ce type de problèmes, la solution la plus couramment utilisée consiste à faire périodiquement des sauvegardes des données de la base sur un autre support (bande magnétique, Disque optique, etc.).
Cette sauvegarde peut alors se faire à plusieurs niveaux :
- sauvegarde de certaines données de la base
- données d'un utilisateur ou groupe d'utilisateurs
- données associées à un projet
Cette sauvegarde doit pouvoir se faire sans perturber le travail des utilisateurs, c'est-à-dire sans qu'il soit nécessaire d'arrêter la base, on parle alors de sauvegarde en ligne (on-line backup). Elle doit également pouvoir se faire de façon incrémentale.
Lié aux opérations de sauvegarde, il peut aussi exister des opérations d' archivage , visant à décharger de la base un certain nombre de données qui ne sont plus directement utilisées, mais que l'on désire néanmoins conserver.
Transfert entre bases
Egalement lié aux opérations de sauvegarde, il peut être nécessaire de transférer des données d'une base à une autre. On parle alors d'opération d'exportation et d'importation des données.
Recompactage, réorganisation physique
Il peut être nécessaire de réorganiser périodiquement les données pour compacter la base. Il faut aussi parfois déplacer physiquement les données par exemple lors de l'ajout d'un nouveau disque sur le système.
De même les opérations de création ou de destruction d'index, ou les opérations de regroupement de données (création de grappes ou "cluster") sont normalement à la charge de l'administrateur de la base de donnée.
Toutes ces opérations ne doivent avoir aucune répercussion sur les programmes applicatifs. Elles n'ont pour objet que d'améliorer la vitesse et les performances de la base.
C'est à ce niveau que l'on peut voir si le concept d'indépendence entre les données physiques et les données logiques est bien respecté.
Outils de suivi (monitoring)
Toutes ces opérations d'administration que nous venons de voir supposent l'existence complémentaire d'outils permettant de connaître en temps réel l'état, les performances et l'utilisation de la base. Ces outils doivent permettre de visualiser le fonctionnement de la base afin d'en régler aux mieux les paramètres.
Le réglage et l'optimisation (le "tunning") des paramètres de fonctionnement d'une base de données sont souvent très complexes, et c'est là qu'intervient tout l'art d'un bon administrateur.