
Typologie des SGBDO
Ces quelques dernières années ont vu apparaître dans le domaine des bases de données un ensemble de nouveaux concepts. Ces concepts ont pour nom : système de gestion de base de données extensible, gérant d'objets, serveur d'objets, mémoire persistante, langage objets persistant, modèles sémantiques, base de donnée relationnelle étendue, base de donnée objets. De même on a commencé à voir apparaître sur le marché tout un ensemble de produits se réclamant tous plus ou moins de l'approche objet, sans qu'il soit toujours facile de savoir ce qui se cache réellement derrière cette étiquette commerciale d'objet.
Il semble donc important de prendre le temps d'essayer de mieux définir ce qui se cache réellement derrière tout ce vocabulaire pour pouvoir comprendre et analyser les différents produits du marché en terme de fonctionnalités. Nous allons donc tenter une telle classification, le but étant de permettre de choisir le type de produit le mieux approprié vis-à-vis des spécificités du problème que l'on cherche à résoudre.
Notre but n'est pas ici de faire un comparatif des différents produits commerciaux existants. On pourra trouver de tels comparatifs notamment dans [Arnaud et Bernier 92], [Ahmed et all 91].
Nous préférons ici illustrer la diversité des différents types de bases de données objets en présentant l'architecture générale de plusieurs de ces systèmes. Chacun des systèmes que nous avons choisis de présenter est en effet représentatif d'un type particulier d'architecture. Les systèmes que nous allons présenter ont été choisis, soit parce que nous avons pu les évaluer réellement (cas de G-Base et de Versant), soit parce qu'ils avaient bien été décrits dans la littérature.
Rappel sur les bases de données
Nous avons vu précédemment qu'une base de données pouvait être définie par quatre concepts clefs :
- Le stockage permanent de données
- Le partage des données entre utilisateurs multiples
- La gestion des ces données indépendamment de tout applicatif.
Parmi ces quatre points, il faut insister sur deux d'entre eux qui nous paraissent extrêmement importants. Une base de donnée a pour rôle essentiel d'assurer la permanence d'un certain nombre de données, et de permettre le partage de ces données entre plusieurs utilisateurs.
Ces 2 aspects constituent le cur d'une base de donnée, et c'est sur ceux-ci que l'on doit avant tout la juger. Une "soit disant" base de donnée qui n'assurerait pas parfaitement ces deux rôles n'a strictement aucun intérêt, car elle est impropre à assurer l'intégrité des données qu'on lui confie.
L'architecture générale d'une base de données objets dépend souvent du domaine de compétence initial de ses concepteurs. Il existe 3 grands types d'approches :
(1) Extension d'une base de données "classique" vers le modèle objet.
Exemple : POSTGRESS (université de Berkeley)
(2) Doter un langage objet de capacité de stockage.
Exemple : SMALLTALK --> GEMSTONE.
(3) Créer un nouveau langage en privilégiant à la fois la richesse du modèle de représentation et l'efficacité du stockage disque.
Classification des SGBDO
Nous avons tout d'abord choisi de classer les systèmes de gestion de base de données objets en trois grandes catégories :
· Les systèmes de mémoire persistante
SGBD orientés objet
Les SGBD "réellement" objets offrent à la fois les fonctionnalités des langages orientés objet et celles des systèmes de gestion de base de données. Il se distinguent par la nature de leur modèle objet. Il existe alors deux grandes options :
· les SGBDO basés sur un langage objet déjà existant tels que C++, CLOS ou SmallTalk auxquels ils apportent une gestion de la persistance, et des fonctionnalités de type base de données.
· les SGBDO ayant un modèle de données propre et donc indépendants du langage utilisé pour manipuler ces données.
Systèmes de mémoire persistante
Un système de mémoire persistante fournit un système de stockage à long terme, et la sauvegarde des objets de tous types et de structure complexe situés en mémoire virtuelle. Ce système est basé sur un modèle abstrait de mémoire uniforme qui supprime toute distinction entre les objets volatils (structure de données en mémoire), et les objets persistants (fichier et base de données).
SGBD extensibles
On doit plutôt les considérer comme des sortes de boîtes à outils permettant de construire leur propre SGBD. Ils offrent en général un certain nombre de modules paramètrables : système de stockage et de reprise sur panne, système de contrôle de concurrence, système d'indexation, gestionnaire de requêtes, etc...
Ils trouvent leur intérêt dans des applications (par exemple les systèmes d'information géographiques) ou la nature particulière des données impose des stratégies très spécifiques de stockage, d'indexation et de contrôle de concurrence.
Critères de comparaison
Architecture générale
Il s'agit tout d'abord de connaître l'architecture générale du système. Le stockage et la gestion des données est-il centralisé ou bien distribué ? Comment communique-t-on avec la base de données : de façon synchrone ou bien de façon asynchrone ? La base de données est-elle capable de fonctionner en environnement hétérogène ? Parmi les architectures les plus couramment rencontrées, on peut citer :
- client/serveur en environnement homogène.
- client/serveur en environnement hétérogène.
Modèle de données
Modèle objet
Quels sont les particularités du modèle objet utilisé ? Certains SGBDO utilisent un modèle dérivé d'un langage objet existant (C++, CLOS, SmallTalk), d'autres proposent leur propre modèle objet.
Identifiants
Un autre choix qui doit être fait est celui de la représentation des références sur un objet chargé en mémoire. Doit-on utiliser de véritables pointeurs (pour des raisons de vitesse) ou doit-on passer systématiquement par un niveau d'indirection entre un identifiant d'objet unique (UID) et l'objet en mémoire (utilisation de "smart" pointers).
Persistance
Un autre point est de savoir comment un objet est rendu persistant. De façon idéale, la persistance d'un objet doit être une caractéristique orthogonale aux autres caractéristiques de l'objet. Nous avons vu qu'il existe plusieurs possibilités pour rendre un objet persistant.
- Par instanciation à partir d'une classe persistante
- Par envoi de message rendant l'objet persistant.
Relations
Quels sont les mécanismes permettant de construire et de manipuler des relations entre les objets en base de données ?
Stockage des données
Architecture du système de stockage
Nous avons vu qu'une des décisions fondamentales de conception d'une base de données est le choix de la granularité d'interaction avec la base. On retrouve ce paramètre à la fois au niveau des échanges entre serveur et client, et au niveau des mécanismes de contrôle de concurrence (verrouillage). Les niveaux de granularité les plus courants sont :
ObServer : un gestionnaire d'objets
Présentation
ObServer est un serveur d'objets à usage général développé à Brown University [Skarra et al. 86]. Le but d'un tel système est d'offrir des primitives de stockage permanent pour un certain nombre de structures de données élémentaires (enregistrement, liste, arbre, etc.). Il gère le stockage secondaire, le groupement et le verrouillage des objets, et offre plusieurs protocoles de gestion des transactions.
Les auteurs ont également développé un langage, ENCORE (pour Extensible and Natural Common Object REsource), servant de modèle de données et de langage de manipulation pour ObServer.
Stockage des données
Architecture du système de stockage
Dans la première version d'ObServer [Skarra et al. 86], le serveur gère 3 fichiers :
- Un fichier Index qui stocke les UID
- Un fichier Entité où sont stockés les objets eux-mêmes
- Un fichier Log pour assurer l'intégrité des transactions.
Les UID sont codés sur 32 bits, et sont alloués séquentiellement par le serveur lorsqu'un client demande la création de nouveaux objets. Cela permet d'organiser de manière efficace le fichier index, et d'accéder à l'identifiant d'un objet en un seul accès disque.
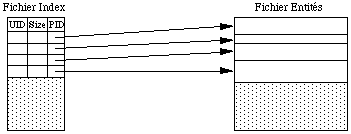
Principe général du système de stockage d'ObServer.
En plus de l'identifiant, on stocke aussi dans le fichier index la taille de l'objet, on peut alors charger l'objet lui même en un seul autre accès disque sur le fichier entité.
Lorsqu'un objet est supprimé, son entrée dans le fichier index est marquée comme référençant un objet détruit, mais l'entrée elle-même n'est par réutilisée, car cet objet peut encore être référencé par d'autres objets dans la base.
Mécanismes de reprise sur panne
Les objets sont toujours écrits dans le fichier entité dans un espace libre. Les anciennes valeurs restent donc toujours accessibles. Un index temporaire chargé en mémoire référence les objets en cours d'écriture par les transactions non validées. Le fichier d'index n'est mis à jour que lors du commit des transactions.
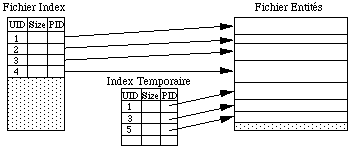
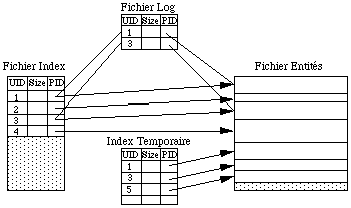
Deuxième phase du commit : mise à jours du fichier Index.
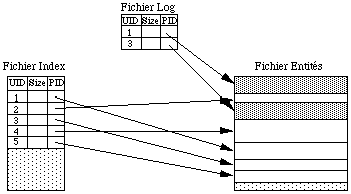
Lors du commit d'une transaction, on utilise un fichier de Log pour enregistrer les anciennes valeurs des entrées dans le fichier index des objets qui ont été modifiés au cours de la transaction, puis on met a jour le fichier index à partir de la table index temporaire. Si tout se passe bien, le fichier Log est ensuite détruit. En cas d'incident, lors du redémarrage de la base, le serveur trouvera un fichier log non vide, et sera capable de revenir à un état cohérent de la base en restaurant les anciennes valeurs du fichier index à partir de celles du fichier Log.
Dans cette première version, le niveau de granularité choisie dans l'implantation est l'objet. Les auteurs ont ensuite fait évoluer le serveur pour lui permettre de manipuler des segments.
Contrôle de concurrence
Gestion des accès concurrents
Afin d'augmenter les possibilités d'interaction avec la base de données, et de limiter les conflits entre utilisateurs, les auteurs ont étendu le système classique de verrouillage à deux phases (two phase lock) en augmentant l'ensemble des opérations utilisables.
Deux grands types d'opérations sont alors possibles.
· Des opérations restrictives (Read et Write).
· Des opérations non restrictives (Nr-Read et Nr-Write).
Ces opérations non restrictives offrent aux utilisateurs des possibilités accrues d'échange d'informations entre transactions au détriment du critère de sériabilité qui n'est alors plus respecté.
L'opération Nr-Read permet de faire des lectures à fin de consultation, sans pour autant entraîner un blocage en écriture pour les autres utilisateurs.
L'opération Nr-Write permet l'échange d'informations entre deux transactions avant la validation (commit) de l'une d'entre elles. Dans un contexte de type C.A.O., cela peut permettre à un utilisateur de voir l'état du travail en cours de l'un de ses collègues au sein de la même équipe de travail.
L'utilisation de ces nouvelles opérations non restrictives reste cependant aux risques et périls des utilisateurs qui doivent bien être conscients que les données qu'ils manipulent alors peuvent être incohérentes.
ObjectStore : un gestionnaire de mémoire persistante
Présentation
ObjectStore est un système de gestion de base de données orientées objets développé par la société Object Design Inc. Il utilise le langage C++ comme langage de définition et de manipulation de données. Sa particularité est d'être basé sur un système de mémoire virtuelle persistante.
Architecture générale
ObjectStore possède une architecture distribuée en environnement homogène. Il gère les transactions réparties grâce à un protocole de validation à deux phases (two phase commit).
Un fonctionnement éventuel en milieu hétérogène est possible à condition que les machines soit basées sur des processeurs manipulant des mots de même taille et de même orientation de bits (little-endian ou big-endian).
Modèle de données
ObjectStore utilise comme modèle de données une extension du langage C++ [Stroustrup 86]. Le schéma de la base est directement dérivé de la définition des classes en C++ par l'utilisation d'un pré-processeur.
Modèle objet
C'est le modèle objet du C++ auquel ont été ajoutées des librairies de classes permettant de gérer des collections d'objets. Il est possible de gérer des liens inverses entre objets par définition explicite d'attributs publics entre les classes concernées.
Identité
Les objets sont référencés directement par un identifiant unique sur 32 bits correspondant à un pointeur dans un segment de mémoire virtuelle.
Persistance
Dans ObjectStore la persistance est orthogonale au type (un même type peut avoir à la fois des instances persistantes et non persistantes) et est obtenue par surcharge de l'opérateur C++ new. Voici un exemple de code montrant l'utilisation d'objets persistant dans ObjectStore.
#include <objectstore/objectstore.H>
// declare une base de donnees et accès a un objet persistant
// de type "pointeur vers un departement"
persistent(db) departement* engineering_departement;
// ouverture de la base de données
db = database::open("/company/records");
// création d'un objet persistant représentant une personne nommée "fred"
employee *emp = new(db) employee("fred");
// on attache la personne au département
engineering_departement->add_employee(emp);
Ce code montre bien que la manipulation de données se fait de façon totalement classique, la seule modification étant ici la surcharge de l'opérateur new pour spécifier que l'on veut créer l'objet emp dans la base de données db
Stockage de données
Architecture du système de stockage
Les bases de données sont stockées au sous forme de fichier ou de partitions au niveau du système d'exploitation UNIX. Chaque base de données est constituée de segments qui correspondent à des parties de mémoire de taille variable. Ces segments sont eux-mêmes formés de pages correspondant aux différentes pages de mémoire virtuelle.
Les transferts entre le client et serveur peuvent s'effectuer, soit au niveau des pages, soit au niveau des segments.
Contrôle de concurrence
Transactions
ObjectStore utilise deux modes de transactions : les transactions en lecture seule et les transactions de mise à jour. Il supporte les transactions imbriquées.
Gestion des accès concurrents
Le système travaillant au niveau des pages de mémoire virtuelle, le contrôle de concurrence s'effectue avec une granularité de verrouillage qui est donc la page. Pour cela, ObjectStore utilise un système de contrôle et de verrouillage à deux phases (two phase lock) au niveau des pages de mémoire virtuelle.
Versant : un langage objet persistant
Présentation
VERSANT est un système de gestion de base de données orientées objets développé et commercialisé par la société Versant Object Technology Corporation. VERSANT offre la persistance et des facilités de gestion de base de données pour des objets C++. Une interface de bas niveau permet également la définition de classes et d'objet à partir du langage C. Versant est un représentant typique d'un langage objet persistant.
Architecture générale
C'est une architecture distribuée en environnement hétérogène. Des clients pouvant posséder une ou plusieurs bases personelles, accèdent via le réseau a un ou plusieurs serveurs contrôlant des bases de groupe (voir See Architecture générale de Versant. ).
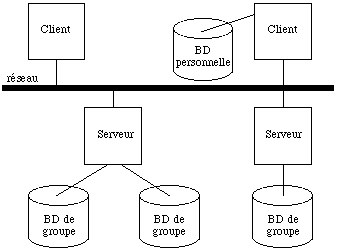
Modèle de données
Modèle objet
Versant utilise les objets du langage C++ [Stroustrup 86] auxquels ont été ajouté des extensions permettant de gérer la persistance. Le schéma de la base est directement dérivé de la définition des classes en C++.
Identité
Versant permet de gérer un nombre important de bases de données (2^16 bases). Un identifiant d'objet est alors formé d'une paire : <Numéro de base | Numéro de l'objet>. L'identifiant dépend donc directement de l'identifiant de la base de données. Il est néanmoins possible de faire migrer les objets de façon transparente entre bases
Persistance
La persistance est obtenue à la fois par héritage de la classe persistante PObject et par surcharge de l'opérateur new. Il est alors possible de définir des objets persistants et des objets temporaires. Un objet instance d'une classe dérivant de PObject peut être :
Relations
VERSANT offre un certain nombre de types d'attributs simples :
o_1b, o_2b, o_4b n-octets signes
o_u1b, o_u2b, o_u4b n-octets non signes
o_float, o_double nombres flottants en simple et double précision
VERSANT offre également un certain nombre de types de relations entre objets :
Link<X> référence a une instance de la classe persistante X
LinkVstr<X> tableau dynamique de références à des instances de la classe
BiLink<X,A> référence bidirectionnelle à une instance de la classe persistante X
BiLinkVstr<X,A> tableau dynamique de références bidirectionnelle à des instances de la
X : nom d'une classe dérivant de PObject
A : nom de l'attribut du pointeur inverse dans la classe X
Versant propose également en standard plusieurs librairies de classes permettant de gérer différents types de collections d'objets :
Container collection ordonnée d'objets hétérogènes
La classe container permet la lecture et l'écriture de son contenu en une seule opération sur le serveur.
V?Set ensemble non ordonné d'éléments de même type
V?List liste ordonnée d'éléments de même type
V?Array tableau d'éléments de même type
V??Dictionary table de correspondance "lookup table"
E : collection de types élémentaires
I : Identité, références à des objets persistants comparés par leur identité
V : Valeur, références à des objets persistants comparés par leur contenu
Pour chaque type de collection est associé un itérateur permettant de parcourir les éléments de la collection.
Gestion de la mémoire
Versant permet une gestion fine de l'utilisation de la mémoire au niveau du cache objet. Il est possible de spécifier le seuil au dessus duquel les objets présents dans le cache seront déchargés ("swapé") sur disque lorsque leur nombre devient trop important. Il est également possible a contrario d'indiquer que l'on désire conserver certains objets en mémoire par un mécanisme de type pin/unpin.
Gestion des exceptions
Le traitement des erreurs au niveau de VERSANT est basé sur le gestionnaire d'exceptions du langage C++ :
(1) Une erreur est levée "thrown" dans un bloc "try block" de code.
(2) Un autre bloc "catch block" capture l'erreur et peut soit la traiter soit la repasser "rethrow".
(3) Si une erreur n'est pas traitée dans le bloc courant, elle est remontée dans le bloc "try" directement supérieur.
Gestion des versions
Versant fournit un mécanisme de bas niveau pour la gestion de versions d'objets. Il permet de gérer pour chaque objet un graphe de versions. Ce mécanisme a pour granularité l'objet, c'est-à-dire que chaque version est un nouvel objet (avec une nouvelle identité). Ce système ne permet pas à lui seul de faire de la gestion de configuration.
Stockage des données
Mécanismes de reprise sur panne
La reprise sur panne s'effectue par utilisation de journaux logiques et physiques.
Requêtes
Versant permet de faire des requêtes simples par prédicat sur des valeurs d'attributs.
Exemple : rechercher tous les pièces de classe vitale qui ont été validées dans la base "PieceCompo".
// definition du predicat de selection
PAttribute("Piece::classe_")==VITALE &&
PAttribute("Piece::validation_")==true;
//execution de la requete, on recupere une liste d'identifiant d'objets
PClassObj<Piece>.select("PieceCompo", FALSE, pred);
Il est également possible de faire des requêtes plus complexes avec parcourt de liens récursif. On peut faire des requêtes du type : rechercher tous les pièces ayant été validées par l'utilisateur dont le nom est "toto".
Le serveur connaisant la sémantique des objets (leur schéma), les requêtes sont évaluées au niveau du serveur, évitant ainsi tout trafic inutile entre le client et le serveur.
Indexation
Pour améliorer les performances des requêtes, il est possible de construire des index sur certains attributs. Ces index peuvent être créés et détruits à l'exécution sans aucune modification du schéma.
Création et destruction d'index sur des attributs
PClass::createindex(<nomAttribut>, <typeIndex>, <nomBD>);
PClass::deleteindex(<nomAttribut>, <typeIndex>, <nomBD>);
On peut spécifier deux types d'index :
O_IT_BTREE : indexation par arbre binaire (ordonnée)
O_IT_HASH : indexation par table de hash (non ordonnée)
PClassObj<piece>.createindex("Piece::numero",O_IT_BTREE,"BDpiece");
Contrôle de concurrence
Transactions
Pour permettre le travail coopératif en environnement distribué, Versant offre deux grand types de transactions.
Les transactions courtes : utilisées lorsque l'on manipule des objets sur de courtes durées.
Les transactions longues : utilisées lorsque l'on doit manipuler des objets sur des durées plus longues (des heures ou des jours).
Lors de l'utilisation de transactions courtes, il est possible de poser des points de reprise (savepoints), et d'utiliser des transactions imbriquées (nested transactions), permettant ainsi d'implanter facilement des mécanismes de type faire/défaire (do/undo).
Les transactions longues se font par l'utilisation d'un mécanisme de check-out/check-in.
Check-out
Un check-out copie des objets depuis une base de groupe vers une base privée de façon atomique (le check-out se fait dans le cadre d'une transaction courte) et en gérant les accès concurents par pose de verrous persistants sur les objets dans la base de groupe. Le mécanisme de check-out copie également si besoin est les classes (le schéma) dans la base privée.
Le check-out peut se faire suivant trois modes de verrouillage : read, write ou snapshot.
Comportement des objets non versionnés
Lorsque des objets non versionnés sont chargés dans une base locale par un check-out avec des verrous en lecture ou en écriture, il sont copiés dans cette base locale mais ils conservent la même identité. Des verrous persistant sont alors posés sur les objets originaux dans la base de groupe.
Lorsque des objets non versionnés sont chargés dans une base locale par un check-out avec des verrous de type snapshot, il sont dupliqués dans la base locale sous une nouvelle identité.
Comportement des objets versionnés
Lorsque des objets versionnés sont chargés dans une base locale par un check-out, une nouvelle version (avec une nouvelle identité) est crée dans la base locale. Il n'y a alors pas pose de verrous dans la base de groupe, et les objets restent disponibles pour d'autres utilisateurs.
Group check-out
Il est également possible de faire des group check-out, c'est-à-dire de copier des objets entre bases de groupe. Ces group check-out ne peuvent se faire qu'en lecture seule (en posant des verrous persistants de type read), et permettent de dupliquer des objets sur plusieurs sites.
Check-in
Le mécanisme inverse du check-out est le check-in. Il peut être explicite, ou implicite par fin de la transaction longue. Une transaction longue peut se terminer soit par une annulation (rollback) soit par une validation (commit). De même que le check-out, le check-in est une opération atomique. Dans tous les cas, les objets lus par un check-out, retrournent dans leur base d'origine à la fin du check-in.
Une annulation restore l'état antérieur de la base de groupe et libère tous les verrous persistants posés sur les objets lors du check-out.
Comportement des objets non versionnés
Les objets verrouillés en écriture remplacent les objets initiaux dans la base de groupe.
Les objets verrouillés en lecture sont ignorés (les objets initiaux sont conservés)
Les objets lus en mode snapshot, ou de nouveaux objets crées, ne sont écrits dans la base de groupe que par un check-in explicite.
Comportement des objets versionnés
Les objets versionnés lus en base privée correspondent à de nouveaux objets, ceux-ci ne sont écrits dans la base de groupe que par un check-in explicite.
Gestion des accès concurrents
Versant propose trois grands types de verrous
- Verrous courts : ils sont utilisés pour verrouiller des objets durant une transaction courte.
- Verrous intensionnels (intention lock) : ils sont utilisés pour le verrouillage des classes du schéma. Ils agissent de la même façon que des verrous courts normaux, mais ils ne sont pas bloquants entre eux.
- Verrous persistants : les verrous persistants sont des verrous posés durant une longue période et pouvant survivre à une panne.
Notification
Versant propose deux mécanismes de notifications : un au niveau de la gestion des verrous, l'autre au niveau de la gestion de versions et du système de checkin/checkout.
Notification d'événement de verrouillage
O_PL_LOCK_BROKEN le verrou vient de sauter
O_PL_REQ_PENDING mise en attente d'une requête de verrouillage
O_PL_OBJ_READY un objet réservé est maintenant disponible
Notifications d'événement au niveau d'un objet
Il est possible de demander au serveur une notification sur les changements d'état de certains objets.
O_VSN_CREATION création d'une version fille de l'objet
Gbase : une base de données objets
Présentation
G-base est issu des travaux de l'université de technologie de compiègne. Développé et commercialisé par la société GRAPHAEL depuis 1986, G-base, grace à son modèle de données PDM se situe a la croisée des concepts d'objet et de réseaux sémantiques.
Architecture générale
Gbase est une base de données objets multi-utilisateurs possédant une architecture de type Client-Serveur en environnement hétérogène. Les données sont stockées sur le serveur, et elles sont accessibles à partir de machines clientes via un réseau. Sur un même serveur, on peut créer et utiliser plusieurs bases (appelées "applications" en termes Gbase).
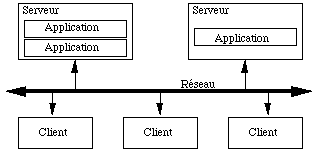
Architecture générale de GBase
Cette architecture permet de mieux répartir la charge CPU entre le serveur et les clients. Les objets sont localement chargés et traités dans un cache au niveau de chaque client. Le serveur se charge lui principalement du stockage et de la gestion de la concurrence entre les différents utilisateurs.
Modèle de données
Modèle objet
Gbase repose sur un micro modèle issu de PDM (Property Driven Model) [Barthès et al 79]. Ce modèle considère que l'on peut représenter le monde réel comme étant constitué d'objets ou entités, ces entités elles-mêmes possédant un certain nombre de propriétés, ces propriétés étant elles-mêmes des objets.
Les éléments de base du micro modèle sont l'entité, les propriétés, les messages et les méthodes. L'ensemble de ces éléments forme le méta-modèle qui est réflexif. Dans Gbase, les objets du méta-modèle sont des objets comme les autres stockés dans la base. De plus ce méta-modèle peut évoluer : l'utilisateur peut le modifier dynamiquement.
Relations
Dans le modèle PDM, on distingue deux types d'attributs :
Ce sont des propriétés qui référencent directement une donnée (une chaîne de caractère, un nombre, etc....), elles correspondent à des feuilles du réseau. Elles sont équivalentes à la notion d'attribut dans le modèle Entité-Relation
Ce sont des propriétés qui référencent d'autres objets, elles correspondent à des arcs entre les différents nuds du réseau. Elles permettent de naviguer dans le réseau. Elles sont équivalentes à la notion de relations dans le modèle Entité-Relation. Les propriétés de structures sont bidirectionnelles via la définition de liens inverses.
Si l'on connecte deux objets par une propriété de structure, le lien inverse est automatiquement mis à jour. Cette mise à jour permet de conserver la cohérence des liens, et ainsi d'assurer l'intégrité référentielle entre objets. Si un objet est détruit, les liens pointant sur cet objet seront automatiquement supprimés.
Gestion des exceptions
GBase définit un certain nombre d'exceptions sous la forme d'objets dont l'un des champs est le type de l'erreur rencontrée. Il offre également au programmeur la possibilité de définir sa propre fonction de gestion d'erreur dont voici un exemple.
(defun MY-ERROR-FUNCTION (error-exception)
(let* ((error-string (gbase-exception-string error-exception))
(error-key (gbase-exception-key error-exception))
(error-args (gbase-exception-arguments error-exception))
(error-msg (apply #'format nil error-string error-key error-args)))
(active-error-pop-up myinter error-msg)
(active-error-pop-up myinter error-msg)
(active-error-pop-up myinter error-msg)
(:UNSPECIFIED-PROPERTY (print "propriete non specifiee")))
Le traitement des erreurs se fait alors en utilisant le mécanisme de gestion des exceptions du Common Lisp (les fonctions Catch et throw).
Stockage des données
Architecture du système de stockage et mécanismes de reprise sur panne
Le serveur Gbase possède deux particularités intéressantes :
Le serveur Gbase est capable de gérer plusieurs disques physiques, et permet de dupliquer les objets entre ces différents disques et ceci de façon transparente pour l'utilisateur. Ce mécanisme permet d'assurer l'intégrité et la continuité de fonctionnement de la base en cas d'incident ou de panne sur l'un des disques (mécanisme de tolérance aux pannes de type "Média failure").
Gestion de l'historique des objets
Dans le serveur Gbase, les objets ne sont jamais réécrits au même emplacement physique, ce qui permet de conserver les anciennes versions des objets, et d'optimiser les opérations de lecture, écriture d'un objet. Nous verrons que ce mécanisme permet également de résoudre de façon élégante certains conflits d'accès.
Contrôle de concurrence
Transactions
Gbase supporte deux types de transactions : les transactions normales (avec pose de verrous) et les transactions d'accès aux versions historiques par la fonction WITH-CURRENT-TIME (sans pose de verrous).
Gestion des accès concurrents
Gbase propose un mécanisme de verrouillage à deux phases au niveau de l'objet (et non de la page). L'existence d'un mécanisme de gestion de versions permet d'accéder à d'anciennes versions sans pose de verrous.
En effet, dans le Serveur GBASE, l'écriture d'un objet se fait toujours à un endroit libre dans la base, et donc l'ancienne valeur de cet objet n'est jamais écrasée. Il est donc toujours possible d'y accéder.
Dans le cadre d'un WITH-CURRENT-TIME, un utilisateur peut accéder en lecture à la dernière version valide d'un ou de plusieurs objets, sans avoir à tenir compte d'éventuels verrous sur celui-ci. Les objets ainsi lus seront toujours logiquement cohérents, car résultant du "commit" d'une transaction précédente. C'est un mécanisme qui permet un accès très rapide en lecture, sans aucun temps d'attente.
Remarques sur l'aboutissement d'un accès:
- G-Base gère les interblocages (verrous mortels). Si un tel cas se produit, la transaction est annulée.
- En cas d'un échec sur un accès (temps d'attente, délai de sécurité), une exception de type échec est engendrée.
- Si une erreur G-Base survient, une erreur Lisp est déclenchée. L'utilisateur a la possibilité de traiter ces erreurs.
Administration de la base de données
Confidentialité et sécurité
Le serveur G-Base distingue deux types de clients (d'utilisateurs) :
- l'administrateur, qui peut détruire, modifier et créer les objets d'un modèle. Il gère la cohérence de la base et son logiciel applicatif.
- l'utilisateur, qui peut lire, détruire, créer et modifier des objets, sauf les objets du modèle.