
Méthodes de conception objets
S'il existe maintenant un certain nombre de méthodes de conception de logiciels par objets, il n'en existe pas réellement qui soit spécifiquement adaptées à la conception de bases de données objets. Nous allons donc passer en revue un certain nombre de méthodes de conception objets pour tenter d'en extraire les idées les plus intéressantes.
On pourra néanmoins trouver dans [Arnold et al 91] une évaluation de plusieurs de ces méthodes et dans [Wilke 93] un résumé, une comparaison et des exemples des méthodes : Booch, Wirfs-Brock, Hood, Coad and Yourdon, Winter Partners, Shlaer and Mellor, Jacobson, Wasserman et al, Rumbaugh, Reenskaug et al, and Colbert.
Nous présenterons tout d'abord la méthode OOA qui est une méthode d'analyse. Sa démarche est très classique, mais elle est très clairement exprimée. Puis nous présenterons la méthode OOD qui est elle une méthode visant plus spécifiquement la phase de conception. Ces deux méthodes, bien que n'étant pas basées sur les mêmes notations, ont en fait un formalisme très proche l'une de l'autre, et se complètent très bien.
Nous terminerons enfin sur un ensemble de conseils sur ce qu'est un bon style de conception et de programmation objet, ainsi que sur les principales erreurs à éviter.
Object-Oriented Analysis (OOA)
Cette méthode s'appuie sur trois grands principes de base permettant d'appréhender et d'organiser un modèle du monde réel [Coad & Yourdon 90].
- La différentiation de l'expérience en objets élémentaires et en leurs attributs
- La distinction entre objets complets et leurs composants internes
- La formation de différentes classes d'objets, et la distinction entre ces classes
L'analyse d'un problème par la méthode OOA se fait en cinq grandes étapes.
- Définir les Attributs (et les connections entre instances)
- Définir les Services (et les connections entre messages)
Nous allons maintenant détailler plus en détail ces cinq étapes. A chacune des ces étapes correspondra un schéma permettant de la représenter.
Identifier les Objets
Cette première phase a pour objet d'identifier les objets dans le contexte du problème à modéliser. L'identification des objets n'étant pas toujours un processus intuitif évident, cette méthode propose un certain nombre de conseils pour nous aider dans cette démarche. Ces conseils abordent notamment des points tels que : où chercher les objets, que rechercher, que prendre en compte et enfin comment nommer les objets.
Où chercher les objets
On doit rechercher les objets dans l'espace du problème à analyser. On étudiera donc tout d'abord le domaine général du problème. Pour cela les auteurs conseillent de demander aux utilisateurs un résumé sur le sujet. Ils conseillent également de consulter une encyclopédie ou des ouvrages de vulgarisations pour pouvoir apprendre la terminologie et principaux concepts du domaine étudié. Il faudra ensuite rechercher les objets dans les documents de spécification (textes, diagrammes) donnés par le client.
Que rechercher
Pour trouver les objets potentiels, on peut essayer de rechercher entre autres : des structures, d'autres systèmes ou mécanismes, des événements enregistrés, des rôles joués, des localisations, et des organisations.
· On peut tout d'abord rechercher des structures préexistantes (classification, et composition) dans le domaine traité. Si de telles structures existent, elles se retrouveront sûrement dans l'analyse.
· Il faut ensuite se poser la question de savoir s'il n'existe pas des systèmes "externes" qui interagissent (qui échangent des informations) avec le système étudié. Si de tels systèmes existent, il faudra surement les prendre en compte dans l'étude.
· On peut chercher l'existence d'événements qui doivent être mémorisés par le système. Si de tels événements existent, il faut en faire des objets.
· Lorsque dans le système, des êtres humains interviennent, quels sont leurs rôles, comment agissent-ils sur les autres objets du système. Par exemple une personne peut être la propriétaire d'un objet, ou être responsable d'un objet. Si de tels rôles existent, il peut être intéressant de les représenter sous la forme d'objets.
· Si le système prend en considération des emplacements, tels qu'adresse ou coordonnées géographiques, il peut être également intéressant de modéliser cette localisation sous forme d'objet.
· Enfin, si le projet se rapporte à des organisations humaines, et si au sein de ces organisations il existe des structures (département, service, équipe, etc....) qui ont un sens pour le projet, il faut sûrement en faire des objets.
Que prendre en compte
Ayant déterminé un certain nombre d'objets candidats pour la modélisation, quels sont les objets que l'on doit réellement prendre en compte et à partir de quels critères doit-on les choisir.
Si l'objet considéré possède plusieurs attributs potentiels qu'il est important de connaître, ou s'il est nécessaire de définir un ou plusieurs services à son niveau, alors cet objet doit être pris en compte dans la modélisation.
Par contre, si l'objet ne semble avoir qu'un seul attribut, et ne pas nécessiter de services particuliers alors, il n'est en général pas nécessaire de prendre en compte cet objet en tant que tel, mais il doit plutôt être pris en compte en tant que simple attribut d'autres objets.
Nommer les objets
Pour nommer les objets, on utilisera un nom, ou un couple nom+adjectif. Le nom d'un objet doit décrire une occurrence unique d'un objet, plutôt qu'un ensemble d'objets. Pour faciliter le dialogue avec les utilisateurs, on utilisera le plus possible le vocabulaire du domaine modélisé.
Notation
La notation utilisée regroupe dans une "boîte" l'ensemble des informations sur l'objet. Elle est représentée sur la See Représentation d'un objet.dans la méthode OOA . On y retrouve trois zones : une pour le nom de l'objet, une pour ses attributs, et une dernière pour ses services.
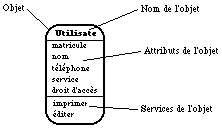
Identifier les Structures
Les structures sont utilisées pour faire face à la complexité du domaine étudié. Elles aident à l'organiser pour pouvoir mieux l'appréhender. On distingue deux grands types de structures : les structures de classification, et les structures de composition.
Structures de classification
L'utilisation de structures de classification est un des principaux moyens utilisés pour organiser la connaissance sur un domaine d'étude. Elle permet le regroupement d'entités en classes, ces classes étant elles-mêmes liées par des liens de type spécialisation et généralisation. Il est ainsi possible de regrouper ensemble des objets ayant le même type d'attributs et le même type de comportement. Pour chaque objet candidat de la modélisation, on cherchera à positionner cet objet par rapport aux autres objets en tant que spécialisation ou généralisation de ces objets.
· On cherchera tout d'abord s'il existe des spécialisations de cet objet qui ont un sens pour l'étude. On cherchera donc des sous-types de l'objet, qui seront plus spécifiques que celui-ci par l'existence d'attributs ou de comportement supplémentaires.
· On tentera ensuite de considérer les objets candidats sous le point de vue inverse, pour chercher s'il n'existe pas un ou plusieurs objets plus généraux permettant de regrouper plusieurs objets ensemble car possédant des caractéristiques communes.
Les regroupements effectués devront avoir un sens dans le cadre de l'étude, et ne pas seulement être dûs à de simples similitudes entre objets.
Structures de composition
L'utilisation de composition permet de représenter les objets sous la forme d'assemblages de type ensemble/sous-ensemble. Il est ainsi possible de percevoir un objet, soit comme un tout, soit comme étant constitué lui même d'autres sous-objets, ces sous-objets pouvant eux mêmes être composés d'autres éléments. Ce type de structure permet donc de modéliser naturellement l'agrégation de composant dans un assemblage. Pour chaque objet candidat de la modélisation, on considérera tour à tour cet objet comme étant lui-même composé d'autres objets ou, au contraire, comme étant un constituant d'un ensemble plus grand.
· Pour chaque objet, on cherchera tout d'abord à le considérer en tant qu'assemblage de composants plus élémentaires. Si de tels composants existent, ont-ils une importance et un sens au niveau de l'étude. Dans ce cas il faudra les caractériser plus complètement.
· Inversement, on cherchera également si un objet ne peut pas être considéré comme étant un composant d'un ensemble ou d'une organisation plus importante. Si une telle structure existe et fait partie du sujet de la modélisation, il faudra la prendre en compte.
Définir les sujets
Si l'espace du problème étudié est important, et donc comporte un grand nombre d'objets, on va rapidement se heurter à des difficultés pour percevoir de façon globale l'ensemble du modèle. La définition de sujets est donc un moyen de structurer le modèle en autant de sous-modèles organisés hiérarchiquement. Cette décomposition en sujets permettra d'avoir une vue d'ensemble du problème. Elle permet également une bonne communication entre les différents acteurs de la modélisation en limitant le nombre d'objets à considérer en même temps.
Pour un projet de taille moyenne (quelques dizaines d'objets), on pourra déterminer les sujets après coup, après avoir identifié les structures. Pour des projets de plus grande importance, on cherchera rapidement à identifier les sujets, pour permettre un découpage de l'analyse.
Définir les attributs et les liens
Les attributs permettent de décrire plus complètement un objet. En définissant les attributs d'un objet, on affine l'analyse, en détaillant quelles sont les propriétés de l'objet que l'on doit prendre en compte et qui ont un sens dans le cadre du problème étudié. A ce stade de l'analyse, il est important de ne choisir que les attributs "pertinents". Par exemple, un attribut couleur pour un outillage de moulage n'a pas à être pris en compte, sauf si cette couleur possède une signification particulière dans l'atelier.
De même, pour chaque attribut, il faut se demander si cet attribut est réellement élémentaire, ou s'il ne référence pas au contraire un objet qu'il faut modéliser en tant que tel. Il pourra éventuellement être bon de repousser ce choix à la phase de conception proprement dite.
Si l'analyse a fait apparaître des structures de classification, on cherchera à mettre en facteur les attributs communs à plusieurs objets au niveau de leur généralisation commune.
C'est également à cette étape que l'on va définir les relations ou liens existant entre les différents objets. Ces liens servent à représenter les relations autres que celles de classification ou de composition qui, nous l'avons vu, ont été identifiés dans l'étape précédente. On établira donc tout d'abord les connections entre les différents objets, puis, pour chaque lien, on déterminera la multiplicité et la participation de cette relation.
La multiplicité d'un lien exprime le nombre de successeurs de ce lien : soit il n'y a qu'un seul successeur et le lien est du type 1:1, soit le lien représente en fait l'association d'un objet avec un ensemble d'autres objets et alors le lien est de type 1:M.
La participation d'un objet à un lien exprime le fait que cet objet puisse ou non exister indépendamment du ou des objets auxquels il est lié. La participation optionnelle à une relation sera représentée par un cercle (un 0), si au contraire elle est obligatoire, on la représentera par une barre (un 1) ( See Notation des cardinalités. ).
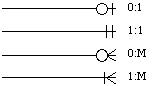
Définir les Services
La dernière étape de l'analyse orientée objet consiste à définir les différents services attachés aux objets. Les services permettent de modéliser le comportement de chaque objet. Ils permettent également de spécifier les interactions de l'utilisateur avec le système, et celles entre les objets du système.
Identification des services
Une première stratégie pour identifier les différents services consiste à considérer chaque objet suivant l'un des trois points de vue suivants :
- actions directes sur l'objet (création, modification, sélection, destruction, ...)
- calculs effectués par l'objet
- attente d'événements (monitoring)
Le premier type (actions directes sur les objets) est tellement commun, qu'il est considéré comme implicite pour tous les objets. On ne le spécifiera que s'il présente des particularités au niveau d'un objet donné.
Une seconde stratégie pour identifier d'autres services est de considérer l'histoire de chaque objet. Au cour de l'existence de l'objet (entre sa création et sa destruction), existe-t-il des actions autres que de le modifier ou de le sélectionner. De telles actions sont alors à prendre en compte.
Une dernière stratégie, est de considérer l'ensemble du système et de ces états, et de voir à quels événements extérieurs il doit répondre. On établira donc un diagramme ou une table état/événement/transition. On identifiera alors quels sont les objets du système concernés par ces événements.
Identification des messages
Une fois les services identifiés, on détaillera les échanges de messages entre les différents objets sous la forme de connections entre ces objets. De même on fera apparaître les commandes provenant de l'utilisateur vers les objets concernés.
Spécification des services
On spécifiera chaque service, en prenant bien soin de considérer ce service uniquement du point de vue du comportement externe de l'objet. Que demande-t-on à l'objet, et de quoi est-il responsable ? La description du service se fera sous la forme de texte décrivant le service.
Object-Oriented Design (OOD)
G. Booch a établi dans plusieurs de ses articles [Booch 81], [Booch 86] et son ouvrage [Booch 91] les principales étapes conduisant à la décomposition d'un programme selon la méthode de conception orientée-objets. Ces étapes ont été reprises dans leurs grandes lignes par toutes les méthodologies parues depuis.
· Identifier les objets et les classes
Cette première étape vise à identifier les objets du monde réel que l'on voudra réaliser. Pour cela, on doit identifier les propriétés caractéristiques de l'objet. Cette étape est bien entendu celle qui demande le plus de talent et d'expérience personnelle. Un moyen relativement informel pour identifier les objets consiste à faire une description littéraire (en français) du problème. On pourra déduire les bons candidats des noms utilisés dans cette description, et leurs propriétés des adjectifs et autres qualifiants.
· Identifier la sémantique des objets et des classes
On cherchera ensuite à identifier les actions que l'objet subit et provoque. Les verbes utilisés dans la description informelle de l'étape précédente fournissent de bons indices pour l'identification des opérations. C'est également à cette étape que l'on pourra définir les conditions d'ordonnancement temporel des opérations, si nécessaire.
· Identifier les relations entre les objets et les classes
L'objet étant maintenant identifié par ses caractéristiques et ses opérations, on définira ses relations avec les autres objets. On établira quels objets le "voient" et quels objets "sont vus" par lui. Autrement dit, on insérera alors l'objet dans la topologie du projet. On définit également l'interface précise de l'objet avec le monde extérieur. Cette interface spécifie exactement quelles fonctionnalités seront accessibles et sous quelle forme.
· Implanter les classes et les objets
La dernière étape consiste, bien entendu à implanter les objets en écrivant le code correspondant aux spécifications dans un langage de programmation. Lors de cette étape, on identifiera de nouveaux objets de plus bas niveau d'abstraction, ce qui provoquera l'itération de la méthode.
Outils de modélisation
La méthode de G. Booch, très complète, offre des outils permettant de couvrir tous les besoins possibles en matière de conception de systèmes informatiques de tous types. Il n'est néanmoins pas toujours nécessaire d'avoir recours à la totalité de ces outils dans le cadre d'un cas précis. C'est pourquoi nous n'allons présenter ici que les concepts qui nous paraissent les plus intéressants dans le cadre de la modélisation d'une base de données objets.
Les vues du modèle
Il n'est pas possible, sauf pour des cas d'école vraiment simples, de représenter de façon unique, c'est-à-dire à l'aide d'un seul diagramme, toute la complexité d'un logiciel. Il est en général nécessaire d'aborder la conception selon plusieurs vues différentes. G. Booch a identifié quatre points de vue fondamentaux : qui sont complémentaires deux à deux :
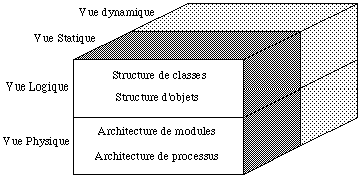
Modèles logiques et physiques
Ils permettent de faire la distinction entre ce qui relève de l'analyse du problème (modèle logique) et ce qui relève de son implantation informatique (modèle physique). On utilisera pour cela quatre types de diagrammes :
Modèles statiques et dynamiques
Les quatre types de diagrammes précédents, décrivent essentiellement la structure statique du problème. Pour en décrire l'aspect dynamique, comment les objets sont créés puis détruits, comment ils s'échangent des messages, on utilise deux autres types de diagrammes :
Diagrammes de classes
Un diagramme de classes permet de représenter les différentes classes et leurs relations au sein du système à modéliser. Un diagramme de classes est construit à partir de trois composants de base : les classes, les relations et les utilitaires de classe.
Classes
Le symbole ci-dessous représente une classe. Son icône (une sorte de petit nuage avec des frontières en pointillé) symbolise le fait qu' une classe est en fait une abstraction .

Relations entre classes
Dans un diagramme de classes, on peut exprimer les types de relations suivants : relation d'héritage, relation d'instantiation, relation de classe à méta-classe et relation générale d'utilisation par une classe A des ressources d'une classe B. Dans ce dernier cas, on peut indiquer les cardinalités de la relation. La représentation de ces différentes relations est illustrée par la See Les différents types de liens. . Chaque type de relation peut être désigné par un label qui permet de documenter le nom ou le rôle de la relation.
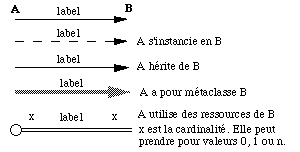
Utilitaires de classes
La conception d'un programme sous forme objet fait souvent apparaître de nouvelles classes non directement issues de l'analyse, mais servant à implanter des fonctions purement informatiques utilisées par les autres classes. On parle alors d'un utilitaire de classe. Un utilitaire de classe correspond, d'une manière générale, à un sous-programme ou un ensemble de sous-programmes indépendants. Un utilitaire de classe est symbolisé de la manière suivante :

Catégorie de classes
Une catégorie apparaissant dans un diagramme de classes correspond à un ensemble logique de classes ou de catégories de classes et fait elle-même l'objet d'un diagramme. Cette notion permet de définir l'architecture logique générale d'une application au moyen du diagramme de plus haut niveau, puis d'affiner la conception en détaillant successivement différents niveaux de diagrammes pour aboutir à la définition de l'ensemble des classes du système. Une catégorie de classes correspond à un ensemble logique de classes ou de catégories de classes et fait elle-même l'objet d'un diagramme. Nous allons présenter ci-dessous les concepts utilisés dans les diagrammes de classes, ainsi que les éléments graphiques constituant les schémas associés.

Visibilité des classes à l'intérieur d'une catégorie de classes
Il s'agit de représenter le fait qu'une classe décrite dans le diagramme associé à une catégorie est visible ou non par d'autres catégories. La notation relative à la visibilité d'une classe est la suivante:
- lorsque le nom apparaissant sur le symbole d'une classe ne possède aucun signe distinctif, il s'agit d'une classe Privée de la catégorie dans laquelle elle est décrite;
- lorsque ce nom est encadré d'un rectangle, la classe décrite dans la catégorie est exportée, c'est-à-dire utilisable par d'autres catégories;
- lorsque ce nom est souligné, la classe est simplement importée dans la catégorie, et décrite dans une autre catégorie dont elle est exportée.
Il est possible de représenter une catégorie dont toutes les classes sont exportées, puis importées par toutes les autres catégories. Il faut pour cela inscrire le mot "global" dans le coin inférieur gauche du rectangle symbolisant la catégorie ( See Représentation d'une catégorie globale. ).

Diagrammes de transition d'états
Comme nous l'avons dit, les diagrammes de classe permettent de documenter l'aspect statique d'un système. Pour symboliser son aspect dynamique, on utilisera alors des diagrammes de transitions d'états. Un diagramme de transition d'état représente l'ensemble des états d'une classe, les événements qui déclenchent la transition d'un état à un autre et les actions qui résultent d'une telle transition.
Diagrammes d'objets
Le but de ces diagrammes est d'illustrer la sémantique de certains points particuliers de la conception en détaillant les interactions possibles entre objets. Trois notions sont représentées sur ces diagrammes: les objets, les liens entre objets et la synchronisation des messages allant d'un objet à un autre. La See Représentation d'un objet. ci-dessous montre le symbole utilisé pour représenter un objet.

Représentation d'un objet.
Une agrégation d'objets peut, en reprenant la même notation, être modélisée par l'icône d'un objet à l'intérieur duquel apparaît une série de symboles d'objets empilés. Cela permet par exemple de représenter les ensembles ou listes d'objets ( See Représentation d'une agrégation d'objets. ).

Représentation d'une agrégation d'objets.
Dans un diagramme objet, un lien entre deux objets symbolise simplement le fait que ces objets peuvent s'échanger des messages. Il est représenté par un trait direct entre les objets. Les messages eux-mêmes sont représentés par une flèche parallèle à ce lien et portant, en étiquette, la liste des noms des messages échangés dans le sens indiqué par la flèche.
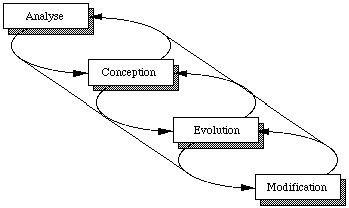
Cycle de développement
Dans son ouvrage, G. Booch propose de conduire le développement suivant un cycle de conception incrémentale en quatre étapes, illustrées par le diagramme suivant ( See Cycle de développement en conception objet. ).
Mise en uvre de l'approche objet
Les conseils
Utiliser le maquettage et le prototypage
Il y a souvent une dichotomie entre la phase de conception d'un système informatique et la phase d'implantation pratique avec un SGBD ou un système de représentation des connaissances. Souvent les délais sont trop longs, et les besoins évoluent rapidement au cours du temps. Cette séparation se traduit souvent par un décalage entre les attentes de l'utilisateur et le logiciel réellement livré "design mismach"[Escamilla et al 90].
Il est donc souhaitable d'intégrer à la base des mécanismes d'extensibilité dans le modèle de données utilisé, pour permettre l'évolution progressive des applications, et une méthode de conception incrémentale. Un des gains essentiels de la programmation objet est de pouvoir tester et qualifier progressivement un logiciel, morceau par morceau, classe par classe.
Les études sur les coûts des projets logiciels montrent que les erreurs de spécifications commises tôt et décelées tard engendrent des surcoûts énormes. Il y a deux conséquences à cette constatation.
1) Une attention particulière doit être portée à l'étude préalable et aux spécifications pour éviter que des erreurs passent inaperçues.
2) Comme les erreurs de définition sont inévitables, il est raisonnable d'en limiter les effets en passant au plus tôt à l'expérimentation : c'est la voie du maquettage et du prototypage.
Le maquettage est un développement partiel réalisé rapidement pour mettre à l'épreuve certaines hypothèses. Il y a trois grands usages du maquettage : l'exploration qui est entreprise lorsqu'un nouveau domaine est à l'étude, la vérification et la validation.
1) Le maquettage pour l'exploration permet d'étudier le comportement du logiciel (ex. : performances d'algorithmes, points techniques mettant en cause la faisabilité).
2) Le maquettage pour la vérification permet de vérifier la prise en compte de spécifications particulières (ex. : interface utilisateur).
3) Le maquettage pour la validation permet de s'assurer que les demandeurs, les développeurs et les utilisateurs se satisfont du logiciel proposé (le prototype constitue alors un support de communication technique qui réduit les risques d'incompréhension).
Le maquettage est surtout utilisé au début du cycle de vie lors de l'étape de spécifications afin d'obtenir des spécifications stables. La méthode peut être utilisée pour explorer n'importe quel aspect du logiciel pour lequel les demandes ne sont pas claires ou bien comprises.
La réalisation de la maquette est faite avec des outils logiciels adaptés qui peuvent très bien ignorer certains aspects du système définitif (ex. : robustesse, efficacité, ..., architecture). Le code d'une maquette est censé ne pas être réutilisé (c'est du code jetable). Le développement repart à zéro fort de l'expérience gagnée. La maquette reste néanmoins disponible pour effectuer des tests croisés avec le système réel.
Le prototypage relève d'une approche légèrement différente. Le logiciel est développé par étapes en étendant progressivement ses fonctionnalités. Les prototypes sont des états de développement du futur logiciel qui prennent en compte de plus en plus de détails des spécifications. Notamment les considérations d'efficacité, robustesse et maintenabilité sont prises en compte dès le début du développement (le prototypage lent encourage l'abstraction des données).
Les partisans de cette approche affirment qu'il est vain de vouloir figer des spécifications qui évoluent de toute manière et qu'il convient de procéder par approximations successives (plus le prototype se développe, meilleure est la compréhension des spécifications). L'effet d'une erreur est limitée et n'a pas de conséquence sur l'ensemble du projet. Le prototypage ne fait pas partie du processus classique de développement du logiciel. C'est une alternative au déroulement séquentiel (et rigide) en étapes du cycle de vie.
Le prototypage est une activité qui possède son propre cycle de vie :
Etablir ses objectifs : il est important que le développeur sache pourquoi il réalise le prototype.
- Déterminer les ressources nécessaires.
Il dépend de la nature du prototype. Les prototypes jetables doivent être de faible coût. Pour les prototypes incrémentaux, les considérations architecturales sont prédominantes (ex. : abstraction des données, faible couplage, cohésion forte des modules).
Dès que possible, le prototype est évalué suivant les critères qui ont présidé à son développement.
4) Réutilisation du prototype (retour en 1).
Des études expérimentales ont montré qu'une approche hybride mêlant l'utilisation de méthodes de modélisation de données, avec un prototypage permettait de développer des applications de façon plus rapide [Alavi & Wetherbe 91]. En effet en utilisant une modélisation des données comme étape préliminaire aux phases de prototypage, il est possible de mieux structurer le prototype, réduisant ainsi le nombre de cycle de prototypes à réaliser pour stabiliser les spécifications.
Réutiliser du code déjà existant
Un des grands avantages de l'approche objet est qu'elle offre potentiellement de grandes possibilités de réutilisabilité des développements. Dans l'industrie, par exemple l'industrie automobile, la tendance est à la diminution du nombre de composants, mais aussi à l'augmentation de la personnalisation des modèles. Dans le développement de logiciels, les objets représentent une ébauche de cette même tendance en introduisant la notion de composants réutilisables (les classes) et personnalisables (par dérivation d'une sous classe et surcharge des méthodes).
La réutilisation de ce qui a déjà été fait permet de multiplier l'efficacité de la résolution d'un problème en assurant que le travail déjà accompli, ou le savoir faire acqui dans un domaine similaire pourra être transféré à un même type de problème. On ne réutilise pas un module logiciel pour lui même, mais parce qu'il capitalise toute une expérience humaine sur un problème spécifique. Une des questions clef de la réutilisabilité est : doit-on créer sa propre librairie de composants ou acheter une telle librairie dans le commerce?
Une règle de bon sens est qu'il faut construire soit même ses bibliothèques de module dans les domaines où l'on a une réelle expertise, et utiliser des bibliothèques standards du marché dans tous les autres domaines (qui sont en dehors de son domaine de compétences premier) [Barnes et Bollinger 91].
On peut distinguer deux types de réutilisation.
Elle correspond à une modification locale d'un composant logiciel pour qu'il puisse mieux se conformer à un besoin particulier. Dans l'approche objets on l'obtient par dérivation d'une sous classe à partir d'une classe déjà existante pour pouvoir la personnaliser et l'adapter à une exigence spécifique.
La réutilisation compositionelle
Elle correspond au contraire à une construction au niveau global d'un logiciel par combinaison de modules standards. Dans le cadre de l'approche objets elle correspond à l'utilisation des classes standards que l'on trouve notamment dans le langage Smalltalk.
Il va de soi que l'on utilise en fait conjointement ces deux types de réutilisation. Cette démarche se retrouve de façon très nette en Smalltalk, où écrire un programme revient à rechercher a l'aide du Browser (l'outil de visualisation des classes) un certain nombre de classes dont on va dériver ensuite des sous-classes plus spécifiques. Le programme final sera alors l'assemblage de ces sous-classes avec un certain nombre de classes standards.
Les logiciels ou bibliothèques du domaine public sont en général bien moins bogués que bien d'autres produits. Leur disponibilité sous forme source et leur large diffusion fait que de nombreux programmeurs dans le monde entier les étudient, les modifient et les améliorent de façon continue.
Parmi des exemples célèbres de logiciel du domaine public, on peut notamment citer le système de fenêtrage X-Windows (X11) et l'ensemble des utilitaires Unix "gnu" de la Free Software Foundation.
Dans le domaine de la programmation orientée objet et plus particulièrement pour le langage C++, on peut trouver des librairies de classes telles que les librairies "gnu" libg++ et NIH qui implantent les structures de données classiques (pile, liste, table hash, etc) et des librairies graphiques telles qu'InterViews au-dessus de X-Windows.
Repousser au plus tard les décisions
On peut résumer cette idée par cette citation de Karl Popper : "Ne vise jamais à plus de précision que n'en requiert le problème posé" [Popper 90].
Il semblerait en effet que l'une des différences entre un expert et un novice réside dans le fait qu'un expert repousse le plus longtemps possible un certain nombre de ses choix, évitant ainsi d'entrer trop tôt dans le détail, alors qu'au contraire un novice essayera tout de suite de tout décider et en fera trop dès le départ, prenant ainsi souvent les mauvaises décisions [Thimbleby 88].
La stratégie employée par un expert, qui repousse la prise de décisions fermes, en attendant de découvrir des contraintes et de pouvoir ainsi mieux décider est une heuristique standard de résolution de problèmes.
Il semblerait néanmoins que la majorité des personnes, confrontées à un problème, ont une tendance naturelle à préjuger et à prendre des décisions de façon hâtive et arbitraire. Cette tendance est naturelle car elle permet de réduire à la fois le nombre et la complexité des sous-problèmes à traiter.
Penser abstrait
On peut résumer cette idée par un principe d'économie : chaque fait, méthode, heuristique, doit être placée dans l'objet qui est le plus général et abstrait possible.
Penser local
Un des principes de la programmation orientée objet, est le principe d'encapsulation. Il en découle qu'un objet ne peut connaître directement que son état interne et local. Donc fini les grands COMMON du FORTRAN où tout était partagé par tout le monde. Il faut au contraire que les opérations soit conçues pour n'avoir que des portées locales, et ne faire intervenir qu'un minimum d'autres objets.
Pour cela, certains programmeurs préconisent de se mettre à la place de l'objet, et de penser à la première personne. Un algorithme peut alors se décrire sous la forme d'une sorte de petite histoire : "lorsque je reçois tel message, je regarde dans une de mes variables, et je renvoie un autre message à l'objet qui s'y trouve...".
Pour assurer un bon style de programmation et renforcer ce principe de localité Lieberherr et Holland ont proposé une loi, appelée loi de Demeter [Lieberherr & Holland 89].
Cette loi concerne en fait la façon dont sont écrites les méthodes, et plus particulièrement vise à restreindre la possibilité d'envoi de messages à l'intérieur d'une méthode à un nombre limité d'autres objets. Elle vise à organiser et à réduire les dépendances entre classes, une classe étant dépendante d'une autre dès qu'elle appelle une fonction définie dans cette autre classe.
Loi de Demeter
Elle spécifie que dans une méthode, on ne peut envoyer de messages qu'à :
- des objets passés en argument de la méthode (y compris soit même)
- des objets directement référencés par une variable d'instance
- des objets retournés par un envoi de messages (notamment une création)
- des objets directement référencés par une variable globale
Une version forte de la loi interdit l'envoi de messages aux variables d'instances héritées, limitant ainsi les risques d'incompatibilité en cas de modification de la sur-classe.
Penser en termes de clients/serveur
Une approche de la programmation orientée objet héritée des méthodes classiques de programmation structurée tend à se polariser sur les structures de données (structures de données abstraites). Cette approche présente néanmoins le désavantage qu'elle tend à incorporer des informations de structure dans la définition des classes, rendant celles-ci plus sensibles à un changement d'implantation ultérieur.
Une approche plus pure et moins sensible aux modifications d'implantation consiste à se focaliser en premier sur l'aspect comportement des objets en analysant systématiquement leurs relations en terme de client/serveur [Wirfs-Brock & Wilkerson 89].
Les erreurs courantes
S'il n'est pas toujours facile de définir ce qu'est un bon style de conception et de programmation objet, on peut par contre de façon négative donner un certain nombre de points de repères sur des "erreurs" ou des fautes de style contraires à "l'esprit objet".
Confondre héritage, instanciation et composition
Une des erreurs les plus courantes et les plus graves est de confondre le sens des relations d'héritage (is-a), d'instanciation (kind-of) et de composition (is-part) entre classes et instances. On peut résumer la sémantique de ces trois types de relation de la façon suivante [Yang 90] :