
LE FICHIER REFERENCE
Introduction
Le fichier référence.
Le fichier référence est une base de données utilisée pour la préparation de pièces composites. Cette base contient toutes les informations relatives à la préparation des pièces, sauf la géométrie des trajectoires d'usinage. Elle permet de faire le lien entre la référence GPAO des pièces et les références CFAO des découpes qui composent ces pièces.
Une pièce est constituée sur un outillage par juxtaposition de découpes réalisées à partir de différents tissus. Ces éléments sont présentés au drapeur dans l'ordre correspondant au positionnement des découpes sur l'outillage.
Cette séquence d'éléments de découpes est décomposée en kits de découpes correspondant à l'ensemble des éléments successifs extraits d'un même tissu. Un kit est logé (et transporté) dans une palette.
La réalisation de chaque pièce nécessite donc d'amener plusieurs palettes et un kit de drapage (outillage et composants consommés par l'opération) à un poste de drapage.
Pour des raisons d'optimisation (limitation des chutes), un programme de découpe (DEJET 1300) peut produire plusieurs kits de découpes logés dans des palettes différentes éventuellement affectées à des pièces différentes.
L'obtention des éléments d'une pièce résulte donc de plusieurs programmes de découpe (égal au moins au nombre de variétés de tissus requis) et s'accompagne de la génération de palettes destinées à une ou plusieurs autres pièces.
La gestion de la cellule répond à deux règles fondamentales :
- satisfaction des ordres de fabrication (normaux et en urgence)
- minimisation des stocks intermédiaires
Cette gestion s'effectuera donc en assurant la tension des flux et leur régulation par l'aval. Le pilotage de la cellule consiste donc à :
- asservir la production des pièces cuites sur la demande des stations de polymérisation.
- asservir la production des kits de découpes sur la demande des stations de drapage.
On aurait pu imaginer que la définition des panoplies puisse être élaborée en temps réel en fonction de la demande effective. En fait, compte tenu des coûts matière, il a été estimé plus judicieux (et plus simple à réaliser) d'admettre le principe d'une constitution a priori d'un certain nombre de "panoplies mixtes" qui satisfassent aux impératifs de réduction des chutes. Une panoplie mixte est constituée par regroupement d'éléments de découpes de pièces différentes à réaliser dans le même tissu.
Etude du système productique
Vue fonctionnelle
Fabrication
Activité de préparation de cassettes
L'opérateur assurant cette activité reçoit du superviseur l'ordre de préparation de cassettes et renvoie un compte-rendu. Le besoin de préparation de cassettes peut être évalué à partir du programme de fabrication et n'exige donc pas un pilotage fin de cette activité.
Activité de découpe des tissus
La machine à découper et marquer les éléments d'un ou plusieurs kits de découpes reçoit du système le programme de découpe (downloading). Elle est actionnée et surveillée par un opérateur également chargé de l'approvisionnement amont (montage de la cassette sélectionnée) si l'opération n'est pas automatique.
Le couplage machine-système s'effectue par le truchement de l'opérateur qui reçoit la fiche d'opération et rend compte en fin d'activité de la machine. Ce compte-rendu garantit la libération de la machine, mais ne peut valider le changement d'état de la ou des palettes destinataires du résultat de la découpe.
Activité de palettisation
Le module de palettisation est chargé de la manutention des éléments découpés et de leur dépose dans les palettes réceptrices en fonction des consignes et de l'identification des découpes. La grande variété de découpes rend difficile la manutention et la dépose correcte de ces éléments. De plus, l'existence possible de découpes situées "de front" requiert simultanément une grande promptitude du manipulateur et sa coordination avec la machine.
En conséquence, cette fonction sera réalisable par un opérateur humain (et susceptible d'être automatisée sans révision du principe de pilotage); l'opérateur chargé d'assurer la surveillance de la machine de découpe peut en effet assurer aisément :
- la reconnaissance des découpes,
- l'association code-marquage et palette réceptrice,
- le déplacement de la palette,
Activité de drapage
L'opérateur assurant la fonction de drapage effectue :
1. la réception du kit de drapage,
2. la réception d'une gamme opératoire,
3. la réception d'une palette de découpes,
4. l'installation des éléments de découpe (tel que définie par la gamme),
5. la libération de la palette,
Activité de polymérisation
L'opérateur assurant la fonction de Polymérisation effectue :
- la réception de l'outillage chargé d'une pièce crue,
- la préparation de la phase de polymérisation,
- l'engagement de l'opération sous contrôle de la fiche technique affichée par le système de supervision,
- la livraison de l'outillage chargé d'une pièce cuite,
- le compte-rendu de fin d'activité.
Remarque
La nature des équipements de polymérisation (étuves et autoclaves) et des attributs-cuisson des pièces requiert de la part de l'ordonnancement, l'optimisation des flux de production en vue de faciliter le groupage des pièces en fonction du volume acceptable des équipements et des types de polymérisation.
Activité de démoulage et reconditionnement d'outillage
L'opérateur assurant la fonction de démoulage et de reconditionnement de l'outillage effectue sur commande du superviseur le transfert de la pièce vers la Cellule de Parachèvement et procède à la remise en état de l'outillage.
Le compte-rendu de fin d'activité se traduit par la mise en disponibilité de l'outillage et l'autorisation de lancement de la prochaine pièce de la série.
Identification des stations de travail
Le regroupement au sein de "Stations de Travail" des activités fortement dépendentes conduit à stratifier le système en donnant à chaque Station une identité fonctionnelle et une autonomie la garantissant (cas d'un système très automatisé) d'une capacité de fonctionnement en situation dégradée.
Une Station de Travail constitue un sous-système opérationnel dont les relations avec les autres stations sont aussi réduites que possible (afin de limiter les risques de contagion) et ne s'effectuent qu'indirectement au travers de la fonction de supervision.
A partir de ces critères, les Stations de Travail du système correspondent aux "lieux" intégrant l'ensemble des opérations nécessaires à :
- REALISER DES KITS Station de découpe,
- POLYMERISER, DEMOULER Station de polymérisation.
Celles-ci sont alors uniquement liées par les fonctions de transport et de gestion.
L'analyse de ces trois activités types permet d'identifier les objets manipulés dans la cellule et de définir les "vues" alimentant les entrées et sorties des activités.
Vue ressource
Chacunne des activitées précédentes utilisent un certain nombre de ressources dont il est important de connaître l'utilisation (machines ou outillages) ou la consommation (matériaux, éléments ou produits d'environnement). De tels éléments forment une catégorie d'objets qui sont utilisés comme ressource par les autres objets de la base. Ils sont également susceptibles d'être utilisés simultanément par plusieurs utilisateurs de la base. Ils feront donc l'objet d'un traitement et d'une gestion spécifiques.
Ces ressources pouront soit être gérées de façon globale pour l'ensemble de l'atelier, soit de façon décentralisée au niveau de chaque station de travail.
Vue information
Outre la définition de la pièce provenant du bureau d'études (géométrie et empilement des couches), les différentes autres informations sont celles utilisées par les diverses stations de travail.
Station de découpe
- programmes de découpe (images ruban CN).
Vue organisation
Gestion des resources
Les diverses ressources (machines, matériaux, éléments de moulage ou produits d'environnement) utilisée pour la préparation et la fabrication de la pièce doivent eux aussi être gérés dans la base de données. Ces éléments sont utilisés par tous les préparateurs, et leur gestion doit être centralisée.
On doit de plus tenir compte des approvisionnements, et par exemple remplacer une matière qui n'est plus fabriquée par une matière équivalente provenant d'un autre fournisseur.
Identification des objets, modélisation
Analyse par la méthode OOA
Définition des sujets
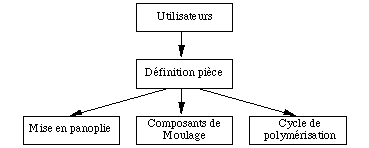
L'analyse de la base de données par la méthode OOA fait apparaître cinq sujets :
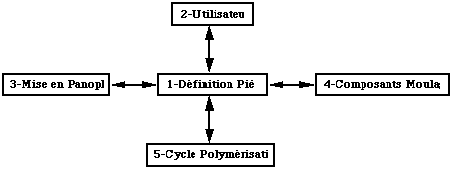
Les différents sujets de l'étude.
- la définition des pièces composites :
C'est le cur de la base de données qui provient de la définition de la pièce par le bureau d'études.
* les pièces, les couches (regroupement de découpes), les découpes et les chutes (internes à une découpe).
* les éléments supplémentaires (inserts, nida...)
* la matière et la variante possible de la matière pour la découpe.
* les marques imprimées sur la découpe.
- la mise en panoplie des découpes :
* les palettes qui sont des regroupements de découpes.
* les références des panoplies figées associées à une pièce, à une palette et à une découpe.
* les moyens de découpes utilisés pour usiner ces panoplies et la découpe.
* les informations pour la prise et la dépose des découpes.
* les produits d'environnement utilisés (tissus d'arrachage...).
* les AOV (Appareillage Outillage Vérificateur).
- la polymérisation des pièces :
* les cycles de polymérisation des pièces.
Diagramme Objet
Il est très simple de passer d'un schéma Entité-Relation (ER) à un premier schéma objet de type OOA
Un schéma Entité-Relation est constitué de trois composants de base : les entités, les attributs, et les relations. Les entités représentent les objets du monde réel à modéliser, chaque entité possède un certain nombre d'attributs qui caractérisent ces entités. Les entités sont reliées entre elles par des relations. Dans le modèle Entité-Relation, les relations peuvent elles mêmes posséder des attributs.
· Les entités du modèle ER se traduisent immédiatement en classes du modèle objet. A chaque entité du modèle ER on fait correspondre directement une classe qui possède les mêmes attributs implantés alors sous la forme de propriétés terminales.
· Les relations du modèle ER se modélisent soit directement sous la forme de propriétés de structures entre classes, soit indirectement en introduisant une nouvelle classe qui portera les attributs et la sémantique de la relation.
Une bonne heuristique pour savoir si l'on doit modéliser une relation par une propriété de structure ou créer une nouvelle classe est la suivante :
- si la relation est intéressante par elle-même, c'est-à-dire que l'on doit manipuler des informations sur cette relation et donc notamment si cette relation porte des attributs dans le modèle ER, alors il faut créer une classe pour cette relation.
- si par contre, la relation n'est utilisée que parce qu'elle est un lien entre entités et rien d'autre, alors il est suffisant de modéliser la relation par une propriété de structure.
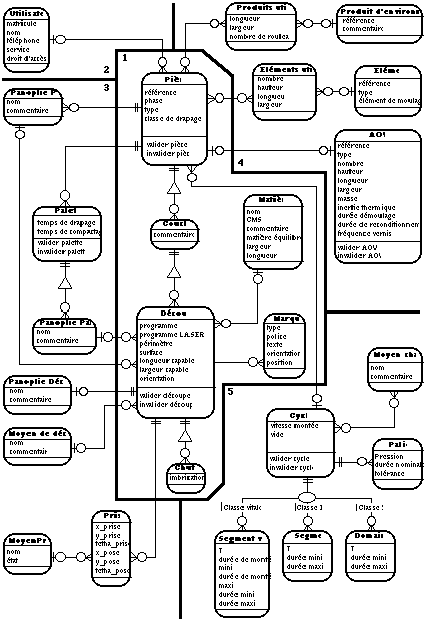
Conception à l'aide de la méthode OOD
La méthode OOD, proposée par G. Booch, va nous permettre de concevoir notre application. Son grand intérêt est quelle permet de bien prendre en compte l'aspect dynamique des données. Grâce à cette perspective, nous pourrons factoriser certains comportements, pour créer des classes d'objets ayant la même réaction à un message.
Ainsi, il sera possible d'extraire des primitives, tant au niveau des éléments qui composent la base, que les liens qui les unissent.
Pour faire le lien avec la méthode OOA, nous allons tout d'abord aborder l'aspect statique des données en commençant par les diagrammes de classes.
Catégories de classes
Comme il est difficile de faire figurer toutes les classes de l'application sur un seul schéma, on a recours à l'utilisation de catégories de classes. Les catégories de classes correspondent à la notion de sujet que nous avons utilisée dans la méthode OOA. On aura donc le schéma suivant :
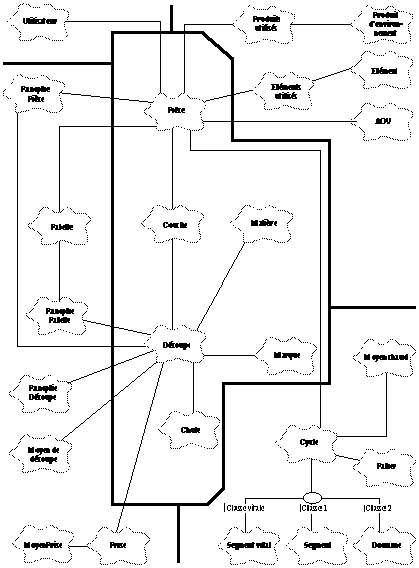
Les différents types d'objets
L'analyse du système productique (et plus particulièrement la vue ressource) a fait apparaître deux grands types d'objets manipulés : les objets définissant la pièce et les éléments de bibliothèque.
On va créer deux grands types d'objets : les objets de définition et les éléments de bibliothèque de ressources.
· Les objets constituant le cur de la définition de la pièce tels que les couches qui composent la pièce, ou des découpes qui composent la couche, vont tous hériter d'une même classe, que nous appellerons nud.
· Les objets qui participent à la réalisation de la pièce tels que matériaux ou produits d'environnement, mais qui sont utilisés par différentes pièces vont tous hériter d'une classe nommée élément de bibliothèque.
Sur tous ces objets, nous pouvons appliquer différentes actions telles que créer un objet, l'afficher, le modifier, ou le détruire. Selon le type d'un objet, on se rend compte qu'il aura un comportement différent, suivant la catégorie à laquelle il appartient. Cela est tout particulièrement vrai pour l'action qui consiste à détruire un objet. Cette action fait bien apparaître la différence de nature et de comportement entre les objets de type nud et ceux de type éléments de bibliothèque.
Diagrammes objets
Pour illustrer notre propos, nous allons utiliser des diagrammes objets pour représenter le comportement de ces différents types d'objets. Cela nous permettra d'identifier différents types de liens entre ces objets, et de mettre en évidence la façon dont les messages sont propagés le long de ces liens.
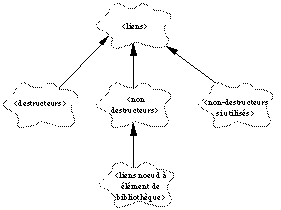
Si l'on efface un objet de type nud par exemple une pièce, il faudra effacer tous ses enfants (les couches, les découpes, etc...) pour que la base reste cohérente. On retrouve donc la notion classique de relation du type est-composant-de (part-of). La See Diagramme objet entre objets de type "noeud". montre comment est propagé un message détruire-objet le long de ce type de relation.
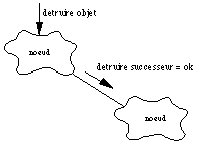
Diagramme objet entre objets de type "noeud".
Si l'on efface un nud (par exemple une découpe), il ne faudra pas effacer les éléments de bibliothèque auxquels il est relié (ici une matière), car ils peuvent servir à d'autres nuds de la base. On met donc ici un autre type de relation de type utilise (use). La See Diagramme objet entre "noeud" et "élément de bibliothèque". montre qu'un lien de type utilise ne propage pas le message détruire-objet vers les objets de type élément de bibliothèque.
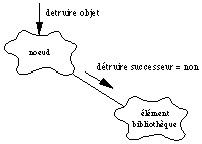
Diagramme objet entre "noeud" et "élément de bibliothèque".
Si enfin on efface un élément de bibliothèque, il faudra vérifier qu'il n'est utilisé par aucun nud. Si un nud utilise un tel élément (par exemple nud "découpe 1" utilise la matière "carbone"), alors l'élément ne pourra pas être effacé (élément "carbone" indestructible). Sinon, il sera envisageable de l'effacer. La See Diagramme objet entre de deux objets de type "élément de bibliothèque". représente le comportement dans ce type de situation.
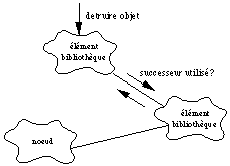
Diagramme objet entre de deux objets de type "élément de bibliothèque".
Nous avons vu qu'il existe donc trois différents types de liens entre les différents objets de la base. Nous avons donc été amenés à créer trois classes de relations :
- Lien destructeur : il propage le message de destruction à l'élément qui est à son extrêmité.
- Lien non destructeur : il ne propage pas le message de destruction à l'élément qui est à son extrêmité.
- Lien non destructeur si utilisé : il ne propage le message de destruction que si l'élément et ses enfants de sont pas utilisés.
D'autre part, la sémantique de l'application nous a amené à créer un type de lien, qui hérite directement des liens non destructeurs : l'effacement d'une panoplie découpe, ou d'une palette ne doit pas entraîner la destruction des découpes. Ces liens sont donc du type liens non-destructeurs. De plus, un élément de type nud est relié à un élément de type bibliothèque par un lien qui est aussi non-destructeur. Pourtant ces deux types de liens n'ont pas tout à fait la même sémantique, puisque l'un relie deux éléments de même type, l'autre non. Un lien de type "lien de noeud à élément de bibliothèque" a donc été créé pour les différencier. Ce lien hérite directement des propriétés du lien de type non-destructeurs.
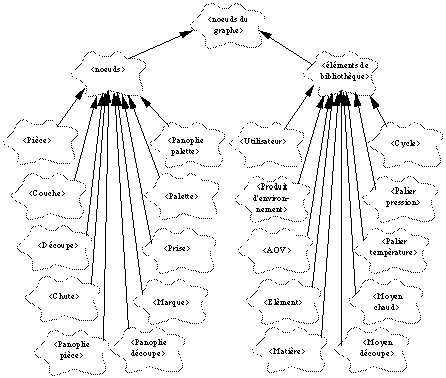
Implantation sur G-Base
Présentation de G-Base
Modèle objet
Les classes
Les classes regroupent les objets (instances) par catégories d'objets ayant les mêmes propriétés. Par exemple, la classe "voiture" regroupe les objets dont les caractéristiques communes sont d'avoir quatre roues, un moteur, des portes, etc...
Les objets construits à partir des spécifications d'une classe sont donc les instances de cette classe. Deux classes peuvent être reliées par des propriétés. Il existe deux sortes de propriétés:
- les propriétés de structure.
Ces propriétés pointent sur d'autres objets. Elles permettent de voir l'ensemble des données au travers d'un réseau. Elles décrivent le réseau sémantique de la base, les relations entre objets. Une propriété de structure représente un lien entre deux objets.
Elles pointent sur une donnée proprement dite ou valeur (un objet Lisp : chaîne de caractères, nombre, etc...). De ces propriétés, on peut parcourir le réseau : ce sont des feuilles qui terminent le graphe.
Le méta-modèle
Le méta-modèle contient l'ensemble des objets nécessaires et suffisants au fonctionnement de G-Base. Le méta-modèle est à la base de toute l'architecture de G-Base. Il est lui même stocké dans la base et peut être modifié par l'utilisateur.
Le méta-modèle comprend la définition de trois classes:
La classe Class est la classe des classes. Elle décrit les propriétés que peut avoir une classe.
La classe Structural Property est la classe des propriétés de structure. Toutes les propriétés de structure existantes dans la base seront donc des instances de la classe Structural Property.
La classe Terminal Property est la classe des propriétés terminales. Toutes les propriétés terminales du réseau sont des instances la classe Terminal Property.
Le méta-modèle comprend, en plus, un certain nombre d'instances de propriétés, c'est-à-dire des propriétés de structure, et des propriétés terminales, permettant de définir ces classes. Le méta-modèle se décrit lui-même, il est donc méta-réflexif (self-reflexive).
Schéma de la base
L'implantation du fichier référence sur G-Base nous a conduit à modifier le méta-modèle. En particulier, nous avons rajouté des classes et des types de liens, qui correspondent aux primitives de la modélisation vues au chapitre précédent. Ces modifications ont permis de personnaliser l'application, mais restent néanmoins très génériques.
Modification du méta-modèle
Pour ne pas modifier directement les classes du méta-modèle, on a rajouté des sous-classes, qui héritent directement de leur parent.
Les sous-classes en question sont:
- "User Terminal Property" qui hérite de "Terminal Property".
- "User Structural Property" qui hérite de "Structural Property".
- "User Class" qui hérite de "Class".
User Class
"User Class" est une sous-classe de "Class".
(list "external name" "user class"
User Terminal Property
"User Terminal Property" est une sous-classe de "Terminal Property" à laquelle on a rajouté des informations utiles pour notre application:
- l'unité attendue (mm, Kg, °C, ...) sert en tant qu'indication.
- le type du champ (alphanumérique, entier, réel...) sert pour vérifier le type des données.
- la taille du champ à éditer (nombre de caractères) sert pour l'affichage.
(list "external name" "user terminal property"
"instance print function" "standard-print"
(list (create-entity "terminal property"
(list "external name" "length-field"))
(create-entity "terminal property"
(list "external name" "unit-field"))
(create-entity "terminal property"
(list "external name" "type-field")))))
(add-superclasses "user terminal property" "terminal property")
User Structural Property
"User Structural Property" est une sous-classe de "Structural Property". A cette sous-classe, on a rajouté trois sous-classes:
- "Destroyable", qui représente les liens destructeurs.
- "No-Destroyable", qui représente les liens non-destructeurs.
- "No-Destroyable-if-used", qui représente les liens non destructeurs s'ils sont utilisés.
De plus, la classe "Noeud-To-Elt-Bib-Link" est une sous-classe de "No-Destroyable".
(list "external name" "user structural property"
"instance print function" "standard-print"))
(add-superclasses "user structural property" "structural property")
(list "external name" "no-destroyable"
"instance print function" "standard-print"))
(add-superclasses "no-destroyable" "user structural property")
(list "external name" "no-destroyable-if-used"
"instance print function" "standard-print"))
(add-superclasses "no-destroyable-if-used" "user structural property")
(list "external name" "destroyable"
"instance print function" "standard-print"))
(add-superclasses "destroyable" "user structural property")
(list "external name" "noeud-to-elt-bib-link"
"instance print function" "standard-print"))
(add-superclasses "noeud-to-elt-bib-link" "no-destroyable")
La See Diagramme des classes du méta modèle. montre la représentation graphique sous forme de diagramme de classes des nouvelles classes du méta-modèle tel qu'il a été implanté.
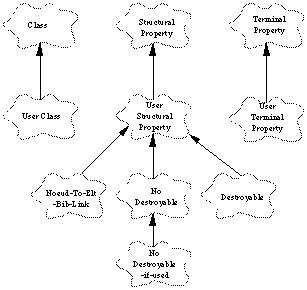
Création du schéma
Création des classes nud et élément de bibliothèque dont vont hériter toutes les autres classes de notre application.
"instance print function" "standard-print"))
(list "external name" "elt-bib"
"instance print function" "standard-print"))
Certaines propriétés terminales telles que date-création ou date-modification étant communes à de nombreuses classes, on va les créer tout d'abord, indépendamment de ces classes.
(create-entity "user terminal property"
(list "external name" "date-creation"
(create-entity "user terminal property"
(list "external name" "date-modification"
Il est ensuite possible de créer toute les autres classes. Nous donnons ici à titre d'exemple les définitions des classes pièce et utilisateur.
"instance print function" "piece-print"
(list (create-entity "user terminal property"
(list "external name" "reference-piece"
"make entry function" "make-entry"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
"type-field" "alphanumerique"))
(get-terminal-property "etat-exploitation")
(create-entity "user terminal property"
(list "external name" "type-piece"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "classe-drapage"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "validation"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "date-validation"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "indice-validation"
(get-terminal-property "date-creation")
(get-terminal-property "date-modification")
(get-terminal-property "date-modification-peripherie")
(create-entity "user terminal property"
(list "external name" "classe"
"type-field" "alphanumerique"))
(add-superclasses "piece" "noeud")
(list "external name" "utilisateur"
"instance print function" "utilisateur-print"
(list (create-entity "user terminal property"
(list "external name" "matricule"
"make entry function" "make-entry"
(create-entity "user terminal property"
"make entry function" "make-entry"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "prenom"
"make entry function" "make-entry"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "telephone"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "service"
"type-field" "alphanumerique"))
(create-entity "user terminal property"
(list "external name" "droit-acces"
"type-field" "alphanumerique"))
(get-terminal-property "date-creation")
Codage des méthodes
Définition d'un message de type détruire un objet :
;------------------------------------------------------------------------------
; Ce message permet de detruire les noeuds, mais pas les elements
; si ce message est envoye a un objet de type noeud, il est efface.
; si ce message est envoye a un objet de type elt-bib, il n'est pas efface.
;------------------------------------------------------------------------------
(create-entity "message" (list "selector" "destroy-object")))
Codage de la méthode de destruction pour les objets de type nud :
;------------------------------------------------------------------------------
; Methode repondant au message "destroy-object-msg" pour les objets
;------------------------------------------------------------------------------
(list "internal function" "destroy-noeud-class-function"
"interpretation of" (list destroy-object-msg)
"method of" (list (get-class "noeud"))))
;------------------------------------------------------------------------------
; Cette fonction s'adresse aux objets de type noeud.
; Elle propage le message de destruction sur le liens directs, puis detruit
;------------------------------------------------------------------------------
(define-service-function "destroy-noeud-class-function" (obj)
;; propager le message le long des liens directs
(dolist (lnk (get-all-structural-properties% (get-class-from-entity% obj)))
(bsend "destroy-link" lnk obj))
(format t "~%effacer le noeud ~S" obj)
Codage de la méthode de destruction pour les objets de type élément de bibliothèque :
;------------------------------------------------------------------------------
; Methode repondant au message "destroy-object-msg" pour les objets
;------------------------------------------------------------------------------
(list "internal function" "destroy-really-elt-bib-class-function"
"interpretation of" (list destroy-object-msg)
"method of" (list (get-class "elt-bib"))))
;------------------------------------------------------------------------------
; Cette fonction sert pour effacer, par exemple une instance de bibliotheque.
; Si aucun de ses enfants n'est utilise, on peut l'effacer.
;------------------------------------------------------------------------------
(define-service-function "destroy-really-elt-bib-class-function" (obj)
(with-slots (l-button l-classes) myinter
;; si l'objet possede des predecesseurs de type noeud, on ne peut pas
(maplist #'(lambda (l) (if (gbase-object-p (car l))
(if (bsend "search-pred" (car l) (cadr l))
"Impossible d'effacer ~:S car utilise par ~:S."
;; Si ce n'est pas le cas, on regarde si les enfants de l'objet en possede.
;; Si oui, on ne peut pas l'effacer.
;; Sinon, on l'efface, ainsi que ses enfants.
(let ((can-delete-children t))
(dolist (lnk (get-all-structural-properties%
(get-class-from-entity% obj)))
(if (bsend "destroy-link" lnk obj)
(setf can-delete-children nil)
Interface graphique
Architecture générale
L'interface utilisée est basée sur une architecture de type Modèle/Vue/Contrôleur (MVC) couramment utilisée dans le domaine des programmes interactifs. Dans ce type d'architecture, une interface utilisateur est construite à partir de trois grands types d'objets:
Modèle : le modèle représente les données de l'application. Il contient ou a accès aux informations à afficher dans les vues.
Vues : les vues sont chargées de l'affichage graphique (ou des sorties sonores); elles utilisent les données du modèle pour les afficher. Un même modèle peut avoir plusieurs vues.
Contrôleur : le contrôleur gère l'interface entre l'utilisateur, le modèle et les vues. Le contrôleur peut être interactif, ou automatique (de type séquenceur).
Ces trois types d'objets interagissent typiquement de la manière suivante : l'utilisateur, via le contrôleur, effectue une opération sur le modèle. Le modèle effectue l'opération demandée, modifiant éventuellement ainsi son état. Le modèle informe alors ses vues de son changement d'état. Chaque vue peut alors interroger le modèle sur son nouvel état, et mettre à jour son affichage si nécessaire.
L'utilisateur peut également agir directement sur les vues (par exemple pour modifier leur apparence)
L'existence d'un modèle objet de la base (le schéma) stocké lui même dans la base de données et accessible aux différents programmes nous a permis de réaliser une interface totalement générique. L'affichage est en effet systématiquement réalisé en utilisant des méthodes propres à chaque classe, et par utilisation du schéma de la base. Nous donnerons ici par exemple la méthode permettant d'afficher les propriétés terminales d'un objet.
;;;----------------------------------------------------------------------------
;;; Cette onction affiche les proprietes terminales de l'objet.
;;;----------------------------------------------------------------------------
(define-service-function "diplay-yourself-function" (obj inst inter)
(let ((tp-name (get-terminal-property-value obj "external name"))
;; la longueur du champ a afficher
(tp-length (get-terminal-property-value obj "length-field"))
;; la valeur du champ (si elle existe)
(tp-value (if (not inst) nil (get-terminal-property-value% inst obj)))
(tp-unit (get-terminal-property-value obj "unit-field"))
;; la propriete est-elle une clef
(ep (get-terminal-property-value obj "make entry function")))
(setf tp-value (format nil "~S" tp-value)))
;; cree un champ texte editable pour la valeur de la tp
:label (if ep (string-upcase tp-name) tp-name)
:displayed-value-length tp-length)
;; affiche l'unite associee a la tp
L'interface réalisée est la suivante ( See Présentation générale de l'interface réalisée. ) :
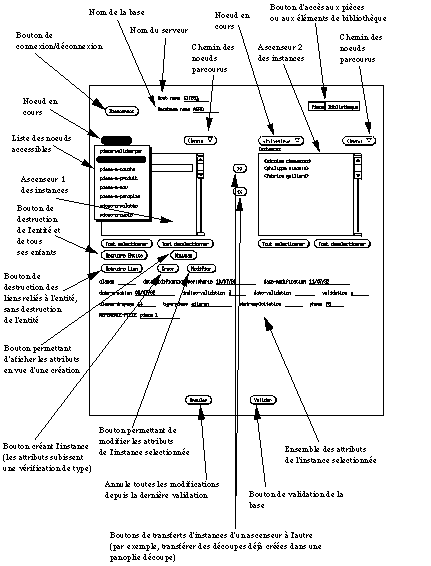
Présentation générale de l'interface réalisée.
L'interface a été développée sur SUN avec le constructeur d'interfaces (interface builder) GUIDE. Cet utilitaire nous a permis de maquetter rapidement l'interface.
Les différentes fonctionnalités sont :
C'est la première étape. La connexion s'établit sur un serveur donné pour une application donnée.
Lorsque l'on termine l'application, il faut se déconnecter du serveur. La déconnexion, par défaut ne valide pas la base.
- la création de nouvelles entités.
Pour créer de nouvelles instances, il suffit de cliquer sur "nouveau", ce qui affiche les propriétés terminales de classe d'objets, puis de remplir les champs, et enfin cliquer sur "créer". Un contrôle d'intégrité se fait lors de l'appui sur "créer". En effet, le logiciel vérifiera d'une part que les types des champs sont bien ceux qui sont attendus, et d'autre part, que la multiplicité (des liens) est correcte.
Permet de modifier une instance. Là-encore, le contrôle d'intégrité s'effectue lors de l'appui sur "modifier".
La destruction d'un objet se fait suivant le processus décrit dans les chapitres précédents. Elle se fait par l'envoi de messages sur les objets, qui eux-mêmes propagent le message.
Cette commande permet à l'utilisateur de valider la base, c'est-à-dire de terminer la transaction. Tant que l'utilisateur n'a pas appuyé sur "valider", toutes les opérations qu'il a faites peuvent être annulées.
- l'annulation des modifications.
Retourne dans l'état de la dernière validation.
Ce module est très important car il permet de travailler sur des modèles qui ne sont pas seulement des arbres, mais aussi des graphes, ce qui est notre cas. Par exemple, on crée une pièce, ses couches, et les découpes associées.
Pour remplir une palette, il faut ajouter des découpes déjà créées dans la palette. Ceci est réalisé par le transfert d'objets entre les deux ascenseurs, à la façon du "Font /DA Mover" sur Macintosh.
Navigation dans la base de données
La base de données peut s'utiliser suivant deux modes.
- Le premier mode s'utilise en préparation : mode création.
Le préparateur est responsable de la création des pièces et de leur validation. Il devra donc, en premier lieu, saisir tous les éléments composant la pièce qu'il désire fabriquer. Ces éléments ne concernent non seulement la géométrie de la pièce, mais aussi toutes les informations relatives à la pièce, telles que les moyens de cuisson, les produits d'environnement, les cycles de température et de pression, les matériaux, etc... Toutes ces données sont regroupées dans la base.
- Le second mode s'utilise en production : mode consultation.
La GPAO établit un programme de fabrication à partir des données du fichier référence. Ce programme de fabrication est ensuite exploité par la préparation automatisée, dont le but est d'une part de mettre en panoplie des découpes suivant les besoins du planificateur, et d'autre part de produire un programme de découpe pour la machine de découpe.
La première étape est la connexion à la base de données. L'utilisateur choisit le serveur et la base auquel il veut accéder et appuie sur le bouton "connect" ( See Connexion à la base de données. ).
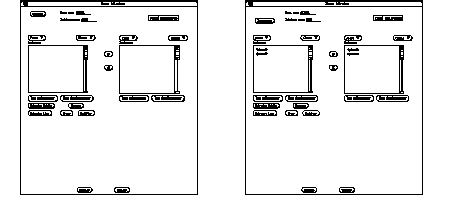
Connexion à la base de données.
L'utilisateur peut ensuite naviguer dans la base de données. Au départ, les deux ascenseurs sont positionnés sur "Pièce" et affichent les instances de "Pièce" déjà créées. A ce stade, on peut choisir une ou plusieurs instances, et effectuer les opérations de création, modification ou destruction. Les attributs (les propriétés terminales) de l'instance de pièce sélectionnée apparaissent sous la forme de champs textes éditables. L'unité de mesure utilisée lorsqu'elle existe, est affichée derrière le champ texte éditable.
Toutes les propriétés de structure (c'est-à-dire les liens qui relient "Pièce" aux autres éléments de la base) sont disponibles via le bouton "Pièce".
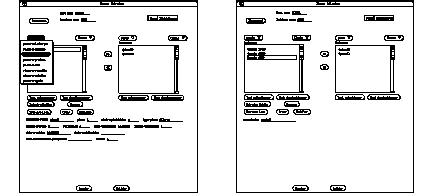
Accès aux propriétés de structure.
Supposons que l'on choisisse la propriété de structure Pièce-à-couche, on va donc pouvoir visualiser toutes les couches de la pièce choisie. Le bouton Pièce va alors se transformer en bouton Couche. Et toutes les propriétés de structure associées à Couche seront disponibles via ce bouton. De plus, le chemin est enregistré dans le bouton Chemin. Ainsi lorsqu'on parcourt le graphe, on peut remonter au niveau désiré, puisque tout le chemin parcouru par l'utilisateur a été mémorisé.
Par exemple, See Utilisation du bouton chemin. , on voit que l'on peut revenir au niveau de la pièce courante simplement en cliquant sur chemin puis Pièce.
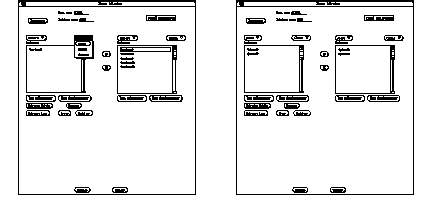
Utilisation du bouton chemin.
Avec l'interface réalisée, le préparateur a la possibilité d'accéder à la bibliothèque à tout moment en cliquant sur le bouton "Bibliothèque". Il pourra ainsi rajouter, modifier et éventuellement effacer (si non utilisé) n'importe lequel des éléments de bibliothèque. La See Accès aux éléments de bibliothèque. montre par exemple comment accéder a la liste des utilisateurs de la base pour l'éditer. On choisit à partir de l'objet Bibliothèque la propriété de structure vers-utilisateur qui permet d'afficher la liste de tous les utilisateurs. On peut alors créer, détruire un utilisateur, ou modifier les attributs d'un utilisateur déjà existant.
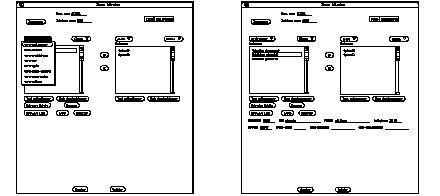
Accès aux éléments de bibliothèque.
En temps normal, la bibliothèque d'objets (matière, cycle, produits, etc...) doit exister et être décrite avant toute création de pièce.
Etablissement de relations entre objets
On veut par exemple renseigner la propriété de structure découpe-à-matière qui associe une matière à une découpe. On va tout d'abord utiliser l'ascenseur de gauche pour naviguer dans la structure de la pièce. Comme nous l'avons vu précédemment, à partir de la racine pièce, nous allons choisir une couche, puis recursivement une découpe. On sélectionne la découpe voulue, puis on visualise la liste des matériaux de cette découpe en cliquant sur le bouton découpe pour choisir la propriété découpe-à-matière. Cette liste est ici vide car on n'a pas encore associé une matière à cette découpe.
On va maintenant utiliser l'ascenseur de droite pour afficher la liste de tous les matériaux disponibles en bibliothèque. Une fois la liste de matériaux affichée, on choisit la matière désirée (ici un carbone), et on l'associe à la découpe en cliquant sur le bouton (<<). La matière sélectionnée apparaît alors dans l'ascenseur de gauche dans la liste des matériaux de la découpe (voir See Choix de la matière d'une découpe. ).
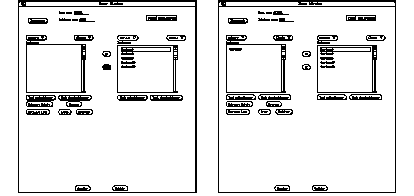
Choix de la matière d'une découpe.
La See Destruction d'un élément de bibliothèque. nous montre ce qui se passe lorsque l'on essai de détruire un élément de bibliothèque qui est référencé par une ou plusieurs pièces. Le système teste systématiquement si l'élément possède encore des liens vers d'autres objets, et si c'est le cas, il affiche un message indiquant que l'opération est impossible.
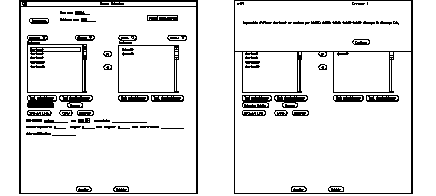
Destruction d'un élément de bibliothèque.
L'interface réalisée a été assez fortement contrainte par l'existence (et la non existence) de certains composant d'interfaces dans la librairie LispViews sur laquelle a été basé notre code. Une librairie plus riche nous aurait certainement permis de développer une interface utilisateur plus riche.
Une Interface encore plus intuitive et conviviale aurait pu être constituée sur un modèle proche du gestionnaire de fichiers que l'on trouve dans l'environnement NeXTStep. Dans cet environnement, les copies de fichiers entre deux répertoires se font par des actions de "déplacer-déposer" (drag and drop). On pourrait envisager d'utiliser ce même type d'abstraction pour implanter une partie des actions que doit réaliser le préparateur. Il choisirait une palette et y déposerait par drag-and-drop les diverses découpes.
Administration de la base de données
Comme nous l'avons signalé dans le chapitre V, il est très important de disposer d'outils permettant d'administrer une base de données. Gbase offre bien de tels outils. La See Le menu d'administration de GBase nous montre le menu général d'administration du serveur.

Le menu d'administration de GBase
Cet environnement d'administration permet entre autres :
- d'initialiser, démarrer ou arrêter une base
- de détruire ou de renommer une base
- de sauvegarder ou de restaurer une base
- de modifier les paramètres de la base ou d'administrer l'espace disque (Silos)
- de visualiser en temps réel le fonctionnement d'une base (voir See Visualisation de l'état de la base. )
- de contrôler le système de recompactage de la base (garbage collection de versions)
Il est à noter et c'est un point très important que les opérations de sauvegarde, de restauration et de recompactage s'effectuent sans devoir à arrêter la base.
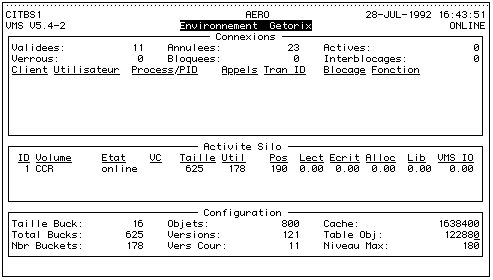
Difficultés rencontrées
Gestion des versions
Si le serveur GBase permet une gestion des versions historiques (graphe linéaire de versions globales) des transactions, le client Lisp que nous avons utilisé ne permet en fait l'accès qu'à la dernière version des objets via la macro with-current-time . Ce mécanisme ne permet donc pas de faire de la réelle gestion de configuration.
Pour pouvoir alors faire de la gestion de versions deux solutions était envisageables :
(1) utiliser un système de versions locales en introduisant un objet générique
(2) utiliser un système de versions globales en utilisant un principe d'annotation
Nous avons vu précédemment que la première solution est complexe à mettre en uvre car elle implique un système de percolation de version.
Nous avons donc choisi la seconde option, en utilisant un système de gestion de version basé sur l'utilisation d'annotations au niveau des attributs des objets.
Pour cela, nous avons été conduit à modifier le méta-modèle de GBase pour y introduire un objet version et deux nouveaux types de propriétés :
· une propriété terminale versionnable : vers terminal property
· une propriété de structure versionnable : vers structural property
;;; modification du meta-modele pour pouvoir gerer des versions
(with-connection (con ("dctks2" "test" :password-function #'superpass))
(let ((class (get-class "class"))
(tproperties (get-structural-property "terminal properties"))
(sproperties (get-structural-property "structural properties"))
(prev (create-entity "structural property"
(list "external name" "prev version")))
(next (create-entity "structural property"
(list "external name" "next version")))
(spsuc (create-entity "structural property"
(list "external name" "vers-sp-successors"
(spsof (create-entity "structural property"
(list "external name" "vers-sp-successors-of")))
(spinv (create-entity "structural property"
(list "external name" "vers-sp-inverse"
;; creation de la classe VERSION
(list "external name" "version"
"instance print function" "version-print"
(list (create-entity "terminal property"
(list "external name" "version name"
;; la classe des proprietes terminales versionables
(list "external name" "vers terminal property"
"instance print function" "vtp-print")))
;; la classe des proprietes de structure versionables
(list "external name" "vers structural property"
"instance print function" "vsp-print"))))
(add-successors vers "structural properties" (list prev next))
(add-successors prev "successors" (list vers))
(add-successors prev "inverse property" (list next))
(add-successors next "successors" (list vers))
(add-successors tproperties "successors" (list vtp vsp))
(add-superclasses "vers terminal property"
(add-superclasses "vers structural property"
(add-successors vsp "structural properties" (list spsuc spinv))
(add-successors spsuc "successors" (list class))
(add-successors spsuc "inverse property" (list spsof))
(add-successors spsof "successors" (list vsp))
(add-successors spinv "successors" (list vsp))
(add-successors spinv "inverse property" (list spinv))
Nous définissons ensuite un certain nombre de méthodes permettant de créer une nouvelle version, de retrouver une version, et de construire la liste de tous les prédécesseurs d'une version.
;; creation d'une nouvelle version de nom <name>
(defun new-version (name previous)
(let ((prev (get-version previous)))
(list "version name" name "prev version" (list prev)))))
;; retrouve une version par son nom
(let ((v (get-entities-from-entry-point name "version" "version name")))
(if (and (listp v) (null (cdr v)))
(raise-gbase-error :undefined-entity "version ~S is not defined" name))))
;; fonction construisant la liste des predeceseurs d'une version
(nreverse (version-list-aux version nil)))
(defun version-list-aux (version vlist)
(pushnew version vlist :test #'object-eq%)
(do-successors ((version "prev version") prev)
(setq vlist (version-list-aux prev vlist)))
L'accès à une version se fera grâce à la macro WITH-VERSION qui construira dans la variable globale *version-list* la liste des prédécesseurs de la version courante.
(defmacro with-version (version &body body)
`(let* ((vers (get-version ,version))
(*version-list* (version-list vers)))
(declare (special *version-list*))
Dans le cadre d'un "WITH-VERSION" il sera alors possible de retrouver, ou de modifier la valeur d'une propriété (terminale ou de structure) par héritage dans la liste des prédécesseurs de la version courante. Pour cela, il nous suffit de surcharger les méthodes d'accès aux valeurs des propriétés terminales et des propriétés de structure.
;;; acces versione a une propriete terminale
(defun get-tp-value (object tp-name)
(get-tp-value% object (get-terminal-property tp-name)))
(defun get-tp-value% (object tp-object)
(alist (get-terminal-property-value% object tp-object)))
(if (setq val (assoc vers alist :test #'object-eq%))
(return-from get-tp-value% (cdr val))))))
(defun set-tp-value (object tp-name value)
(set-tp-value% object (get-terminal-property tp-name) value))
(defun set-tp-value% (object tp-object value)
(let* ((vers (car *version-list*))
(alist (get-terminal-property-value% object tp-object))
(versval (assoc vers alist :test #'object-eq%)))
(push (cons vers value) alist)
(setf (get-terminal-property-value% object tp-object) alist)))
;;; acces versione a une propriete de structure
(defun get-sp-value (object sp-name)
(get-sp-value% object (get-terminal-property sp-name)))
(defun get-sp-value% (object vsp-object)
(alist (get-terminal-property-value% object vsp-object)))
(if (setq val (assoc vers alist :test #'object-eq%))
(return-from get-sp-value% (cdr val))))))
(defun push-sp-value (object sp-name value)
(push-sp-value% object (get-terminal-property sp-name) value))
(defun push-sp-value% (object vsp-object value)
(let ((versval nil) (vers (car *version-list*))
(vsp-inv (car (get-successors vsp-object "vers-sp-inverse"))))
(let ((alist (get-terminal-property-value% object vsp-object)))
(if (null (setq versval (assoc vers alist :test #'object-eq%)))
(if (null (setq versval (get-sp-value% object vsp-object)))
(push (list vers value) alist)
(push (list* vers value (copy-list versval)) alist))
(setf (get-terminal-property-value% object vsp-object) alist))
(let ((alist (get-terminal-property-value% value vsp-inv)))
(if (null (setq versval (assoc vers alist :test #'object-eq%)))
(if (null (setq versval (get-sp-value% value vsp-inv)))
(push (list vers object) alist)
(push (list* vers object (copy-list versval)) alist))
(setf (get-terminal-property-value% value vsp-inv) alist))))
Gestion des états
Une autre contrainte que devait satisfaire le logiciel était de pouvoir gérer au moins deux états des objets :
- un état temporaire pour les pièces en cours de préparation et non encore validés.
- un état définitif pour les pièces validées et entrées en production.
Là encore, GBase ne disposant pas façon native de capacité de type check-in/check-out, il était nécessaire de trouver une solution palliative. Plusieurs solutions ont alors été explorées.
Une première solution envisageable, était de coder la gestion des états de la même façon que celle des versions, en utilisant un système d'annotation au niveau des attributs des objets. Cette solution n'a pas été retenue car, les états étant tous implantés au niveau du même objet, elle n'autorisait pas un bon degré de parallélisme pour l'accès concurrent à plusieurs états.
La seconde solution choisie, a été d'utiliser deux bases de données différentes : une pour les pièces entrées en production, une autre pour les pièces en cours de préparation. Le passage de la base de production à la base de préparation s'effectuant alors par une procédure d'import/export des différents objets entre ces deux bases. Un des inconvénients de cette solution est que les deux bases possédant leur propre gestion indépendante des identifiants d'objets, il n'était plus possible de se baser sur ces identifiants pour repérer un même objet (une même pièce) entre ces deux bases.
On perd alors une partie des avantages associés à la notion d'identifiant unique, car on est alors obligé de revenir à une notion d'identifiant lié à la valeur d'un (ou de plusieurs) attributs pour dénommer un même objet (dans des états différents) entre les deux bases. Par exemple, une même pièce est alors identifiée par la valeur de son attribut référence, supposé unique pour chaque pièce.
Conclusion
Parallèlement à notre travail, le fichier référence a été développé sous Oracle V6 et implanté dans l'usine de production de Marignagne. Les phases d'analyses ont été menées conjointement sur les deux projets et ont abouti à un même schéma entité-association. Même si ensuite les conceptions ont divergé, les deux bases ont été réalisées sur la base d'un même schéma conceptuel.
Cette situation nous place dans un cadre idéal pour faire une analyse comparative des deux solutions utilisées : la technologie relationnelle et la technologie objet.
Comme nous allons le voir, cette comparaison fait apparaître clairement dans tous les domaines les avantages de l'approche objets.
Comparaison avec la solution relationnelle
Simplicité de conception
L'analyse du sujet qui a été menée conjointement pour les deux projets a débouché sur un diagramme entité-association.
Comme nous l'avons vu, le schéma conceptuel OOA de la base peut se déduire presque directement du schéma entité-association. On retrouve également cette même correspondance entre le schéma physique de la base et le schéma entité-association. Les seules différences proviennent de l'utilisation du mécanisme d'héritage des langages objets pour factoriser certaines structures ou comportements.
Au contraire, la conception du schéma physique d'une base relationnelle passe par une étape complexe de normalisation qui transforme le schéma entité-association en un ensemble de tables devant théoriquement être en troisième forme normale. Cette différence profonde entre le schéma conceptuel et le schéma physique complique la tâche du concepteur et augmente le temps de conception.
Codage réduit
Le schéma physique de la base reflétant directement le schéma conceptuel, et étant lui même stocké sous forme objet (les classes) dans la base, il est possible d'accéder directement à ce schéma à partir du code. De plus, l'utilisation du mécanisme d'héritage et l'accès au méta-modèle nous ont permis de mettre en facteur et d'abstraire un certain nombre de comportements, ce qui nous a permis d'obtenir un codage très réduit.
Comme nous venons de le voir, en relationnel, tout le codage doit être pensé en termes de schéma conceptuel, mais codé en fonction du schéma physique. De plus, le schéma physique de la base ne reflétant pas le schéma conceptuel, il n'est pas possible d'utiliser ce schéma pour rendre générique le code. On est donc contraint d'écrire de nombreuses fois du code presque semblable pour différents objets . Le code obtenu est donc beaucoup plus volumineux et souvent très redondant.
Une solution possible à ce problème est de mettre une uvre un système de génération de code. On décrit dans un pseudo langage un schéma de base proche du schéma conceptuel, et on génère automatiquement du code par un processus de type compilation.
Généricité de l'application
Le codage que nous avons réalisé, nous a permis d'exploiter au maximum les possibilités d'accès au modèle et au méta-modèle offert par G-Base. Grâce à cette facilité, le code de l'interface réalisée est totalement générique. Si l'on est amené à modifier le modèle, il ne faudra modifier que le fichier décrivant le modèle, et relancer la base. Rien n'aura besoin d'être retouché au niveau du code de l'interface.
Avec Oracle, tous les écrans que l'on rencontre lorsqu'on navigue dans la base ont été dessinés et figés . Si une modification doit être faite au niveau du schéma de la base, il faut redessiner et réécrire le code du panel correspondant.
Souplesse accrue en mode multi-utilisateur
L'approche utilisée dans les bases de données objets et plus particulièrement son implantation dans G-Base permet une plus grande souplesse d'utilisation en environnement multi-utilisateurs.
Oracle offre un système de verrouillage soit au niveau de la page physique ce qui augmente le risque de conflits lors d'accès à de petits objets (qui peuvent cohabiter sur la même page), soit au niveau de la table (ce qui est inutilisable de façon pratique).
Plus grave, un objet étant en relationnel représenté par des lignes dans plusieurs tables, il n'y a en pratique aucun moyen de verrouiller globalement un objet pour assurer à un utilisateur qu'il est le seul à modifier cet objet . Ce type de comportement, s'il est acceptable en environnement classique (de type bancaire ou de gestion) est très dangereux en environnement d'ingénierie où les objets sont beaucoup plus complexes.
Le système de gestion des accès concurrents se fait dans G-Base par pose de verrous à un niveau de granularité qui est l'objet. De plus ce mécanisme ne pose de verrous que sur les objets qui sont réellement accédés et qui ont été chargés en mémoire. Le verrouillage est donc minimum, limitant ainsi les risques de conflits entre les différents utilisateurs.
De plus, le système de gestion des versions d'objets utilisé dans Gbase (grâce au mécanisme de with-current-time) permet un accès en lecture seule dont le succès est garanti, sans aucun délai d'attente vis-à-vis d'autres utilisateurs. De plus cet accès se fait sans pose d'aucuns verrous et donc sans risquer de bloquer d'autres utilisateurs .
Meilleures performances
Même si nous n'avons pas procédé à des tests comparatifs expérimentaux, il semble que les performances (en terme de temps d'accès pour l'utilisateur) soient nettement en faveur de Gbase par rapport à Oracle. Cela semble logique compte tenu du type de notre application qui consiste essentiellement à naviguer dans une structure de type graphe.
Dans ce type de navigation, les systèmes relationnels sont handicapés par la nécessité de réaliser de nombreuses jointures pour retrouver les bonnes données, alors que la base objet peut y accéder rapidement en suivant les liens entre objets.
Points restant à améliorer
Les points que nous allons aborder concernent des modifications qu'il serait souhaitable d'apporter à GBase en vue de mieux répondre aux besoins d'une base de données d'ingénierie.
Contrôle de concurrence
L'utilisation d'un système de contrôle de concurrence par verrouillage au niveau des objets permet de ne verrouiller que les objets réellement chargés en mémoire et donc de limiter les risques de conflits entre les différents utilisateurs.
Il serait néanmoins possible d'améliorer encore ce système en tenant compte de la sémantique particulière des liens inverses. En effet, avec le système actuel, la mise a jour d'une propriété de structure entraîne le chargement en mémoire (et donc ee verrouillage) de l'objet successeur de cette propriété pour pouvoir permettre de mettre à jour l'inverse de cette propriété.
Si par exemple on veut renseigner la propriété de structure découpe-à-matière qui associe un objet matière à un objet découpe. On va charger en mémoire (et donc verrouiller) l'objet découpe et ajouter dans la propriété de structure découpe-à-matière l'identifiant de l'objet matière choisi. Comme il est nécessaire de mettre à jours le lien inverse matière-de-couche, il faudra également charger en mémoire (et donc verrouiller) l'objet matière pour ajouter dans le lien inverse l'identifiant de l'objet découpe.
On aura donc été obligé de charger en mémoire (en donc de verrouiller en écriture) un objet matière pendant toute la durée de la transaction uniquement pour y mettre à jours un lien inverse, le rendant ainsi non disponible pour tous les autres utilisateurs.
Gestion de versions
Le serveur GBase offre un mécanisme très intéressant de gestion des versions historiques d'une configuration d'objets au niveau des transactions. Il n'est hélas pas possible d'y accéder (hormis la dernière grâce à la macro with-current-time) au niveau utilisateur à partir de l'interface LISP. Un ajout très intéressant serait donc de développer une interface programmeur permettant d'accéder à l'ensemble des versions stockées sur le serveur.
Gestion d'états
Nous avons vu que GBase n'offre pas de moyens simples de gérer plusieurs états d'un même objet (ou groupe d'objets). Cette fonctionnalité est pourtant très importante dans le cas d'une base de données utilisée dans un cadre industriel, où l'on doit toujours pouvoir utiliser un état stable et validé de la base en production, pendant qu'en parallèle on en utilise une autre version pour faire la préparation de nouvelles pièces.
Il serait donc souhaitable que GBase puisse gérer simultanément plusieurs niveaux de bases de données, et possède des mécanismes de type check-in / check-out, permettant de passer entre ces différents niveaux.